业务介绍
中华万年历的头条数据是根据推荐算法聚合而成的数据,包括ALS算法数据、用户画像数据、时效数据、非时效数据、定投数据、惊喜数据、频道数据、热榜数据、用户相关阅读推荐数据等。启动方式分为冷启动和用户画像启动。
- 冷启动:无用户画像或用户画像得分<8分。
- 用户画像:根据用户浏览头条数据给用户打的一系列标签,标签采用Long型的数字进行标记,譬如娱乐285L,旅游1127L。
- 时效数据:和时间相关的数据,会随着时间的推移自动消失,譬如新闻、娱乐。
- 非时效数据:和时间不相关的数据,会长期存在,譬如养生。
- 定投数据:通过管理后台手动投放的数据,一般为固定位置数据,如广告、帖子。
- 惊喜数据:排除画像之外的数据。
- 频道数据:多个标签下的数据组合而成的数据。频道是标签的父类,一个频道对应包涵多个标签,标签是用户画像组成的基本单位。
- 热榜数据:根据用户点击实时上传的日志计算得分较高的数据。
- 用户相关阅读推荐数据:根据用户点击实时上传的日志计算相关联的数据。
数据存储
头条的数据都是从合作方抓取的,通过定时调用第三方API进行抓取。抓取的数据经过频道标签分类后存储到mysql数据库。头条服务会每隔一段时间把数据库里面的数据reload到redis中,然后再从redis中reload到本地内存中。数据的聚合就是把内存中的数据按照算法进行组装。
为什么要经过两次的数据reload,因为我们的接口服务是支持水平扩展的,如果单一的从数据库reload的话,数据库的连接压力会随着服务节点的增加而增大,数据加载不一致的机率会也会增加。使用redis进行中间过渡可以把数据库的压力分担到redis,毕竟redis的并发能力高于mysql,访问速度也高于mysql。
数据reload到本地内存会经过筛选分类,即每种数据在内存中都会有对应的一个数据池,这些数据池是通过reload循环迭代分进去的。
数据池分为:
- 新池子:存放新抓取的非实效数据,数据结构为
Set<Long> - 老池子:存放有点击率、pv的数据,数据结构为
List<Long> - 视频池子:存放所有的视频数据,数据池结构为
List<WnlLifeCardItemBean> - 非实效标签池子:存放标签对应的非实效条目id,数据结构为
Multimap<Long, Long> - 实效标签池子:存放标签对应的实效条目id,数据结构为
Multimap<Long, Long> - 黄历池池子:存放黄历标签下的数据,数据结构为
List<WnlLifeCardItemBean> - 星座池子:存放星座标签下的数据,数据结构为
List<WnlLifeCardItemBean> - 未来天提醒池子:存放投放的电影、体育等节目提醒数据,数据结构为
List<WnlLifeCardItemBean> - TotalMap:加载所有数据的id->bean集合。
除了本地内存的数据池外还有大数据平台推荐的其它数据,该数据存放在redis中,数据结构为Set<Long>
备注: WnlLifeCardItemBean 为返回的头条对象bean,Long类型的是bean对象id或标签id。
数据存储架构图:

早期数据更新方式:
数据更新主要存在两个地方的更新:redis和local。对新抓取的数据在api服务接口中采用spring quartz每隔一段时间从redis中读取一次然后同步到local。redis中的数据则是通过一个单独的bg模块,同样采用spring quartz定时任务每隔一段时间从mysql中读取,然后同步到redis中。除了新抓取的数据外,在每个api服务中还有每秒更新pv、click的定时任务。
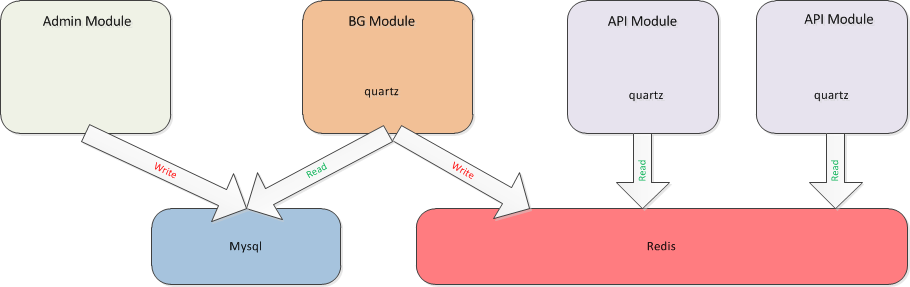
由于我们抓取的数据分为自动上架和手动上架,手动上架需要运营人员审核通过后才能在客户端展示,对自动上架不符合要求的数据也需要做下架处理,按照上面的更新方式显然不能立即生效。
值得思考的问题:
- api节点较多怎么保证每个本地内存中的数据是否一致
- 能否有针对性的更新,不用每次都reload所有数据
- 能否分离api中的定时任务到bg模块
- 能否及时响应数据变化自动更新
遇到的问题
数据更新丢失。bg在更新redis数据时是先添加原数据然后再建立索引,原数据采用String数据结构,bean的ID作为key,序列化的对象作为value。索引采用Set数据结构,value存放的是bean的id。每次更新数据时会删除索引然后重新创建。如果头条接口服务正在reload数据的时候发生bg更新任务则会导致reload到local中的数据丢失。
reload时间过长。头条服务在启动的时候不会立即初始化数据,而是通过用户触发,异步的完成加载。为了避免大量用户并发reload操作采用Cache对操作进行缓存,设置缓存时间的大小。值得注意的是如果缓存设置的时间小于加载的时间则同样会造成并发的reload。
占用内存较大,耗费CPU。随着抓取的数据越来越多,非实效的数据也越积越多,最终导致内存中的数据越来越大,从redis中读取数据进行反序列化需要耗费大量的cpu。虽然限制读取数据的条数可以避免这个问题,但是数据是糅合在一起的,被限制的一部分数据可能是对用户最有价值的数据。
业务数据分离
由于数据种类较多,数据量较大,每次变更一条数据重新reload全部数据会导致内存和CPU迅速上升,尤其是全局的临时变量替换、json的反序列化。这样做不仅重复加载,而且还会因为其它数据加载的失败而影响到所需要的数据,没有做到有针对性的更新。尤其在定投广告数据时,广告需要很长时间才能出现,或是因为没有加载进来不出现,这样就直接影响到了收入,肯定是不允许的。为了减少更新的数据量,把数据按照业务进行分离,每次更新一条数据只reload对应的数据种类。
更细粒度的数据更新可以针对到某一条。由于本系统数据已经按业务进行了拆分,数据量在合理的范围内,做整体替换实现更加简单。
业务数据分离是为了保证最小的数据变动,我们按照业务需求把一条sql拆分了多条sql,每条sql完成对应的数据加载,同样内存中的数据也做了细化。内存中的数据和redis中的数据同步是通过redis的订阅发布实现的。
整体结构如图:
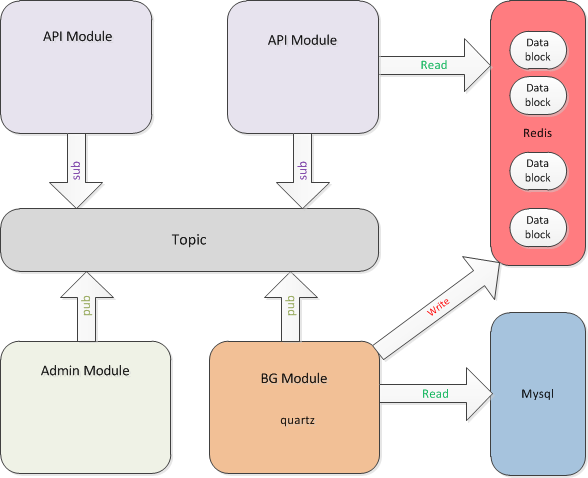
推荐数据迁移到Redis
虽然数据分离解决了一部分reload的问题,但推荐数据是个大的数据块,需要把所有非实效的数据都加载进来,内存压力很大。当初把数据缓存在本地是为了提高客户端的访问效率,但当数据增加到一定程度时,每次进行数据替换都会产生占用内存较大的临时变量,老的变量会被java虚拟机自动回收,所以在数据reload的过程中gc会变得更加频繁。分析解决办法:1、增加机器内存无疑需要增加成本;2、使用增量更新,即针对变化的数据直接在内存中进行修改,不做整体的reload替换,但这样做又引出了新的问题,怎样保证每个节点的数据是否一致,更新失败怎么处理,怎么做到数据有效的监控;3、把数据迁移到redis。
如果按照方法2去实现的话等于是又要造一个redis,所以最终采用了把数据迁移到redis的方式。数据存储主要分为基础数据和索引数据,索引数据是有序的id Set集合,索引按照推荐策略进行了分类,如新闻、频道、曝光、ctr等,通过调用大数据平台来更新索引的分类和Set集合元素的score值,用以保证推荐数据的准确性。
为了减少redis的连接次数,每次推荐都会计算出足够多的数据存放到用户的阅读缓存中,如果用户阅读缓存中的数据不够了会重新触发聚合计算。
数据抓取
头条的数据来源是API接口抓取(经过授权),之前的方式都是针对每一种数据源在bg模块中进行单独开发,然后在xml中配置quartz定时运行任务,没有做到数据监控和可视化管理。如果要停止或修改某一个数数据源的抓取任务必须停止整个bg服务然后再修改代码或quartz配置文件。
修改后的数据抓取框架:
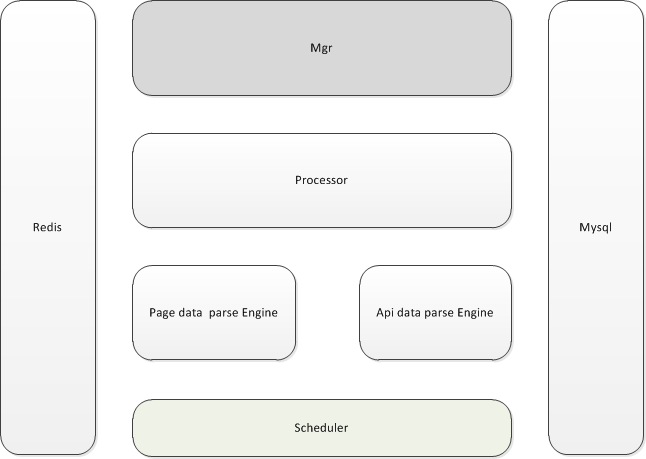
独立出一个专门的数据抓项目ulike,通过后台管理,实现任务的可配置化。
- Mgr 后台管理,管理数据源配置和任务配置,查看抓取的数据以及监控信息。
- Mysql 存储Mgr的管理信息
- Scheduler 负责任务调度
- Redis 调度通过redis发布订阅传给Processor命令,对任务进行操作。
- Processor 负责处理抓取命令,业务处理。
- Engine 对源数据进行解析获取系统所需要的数据。
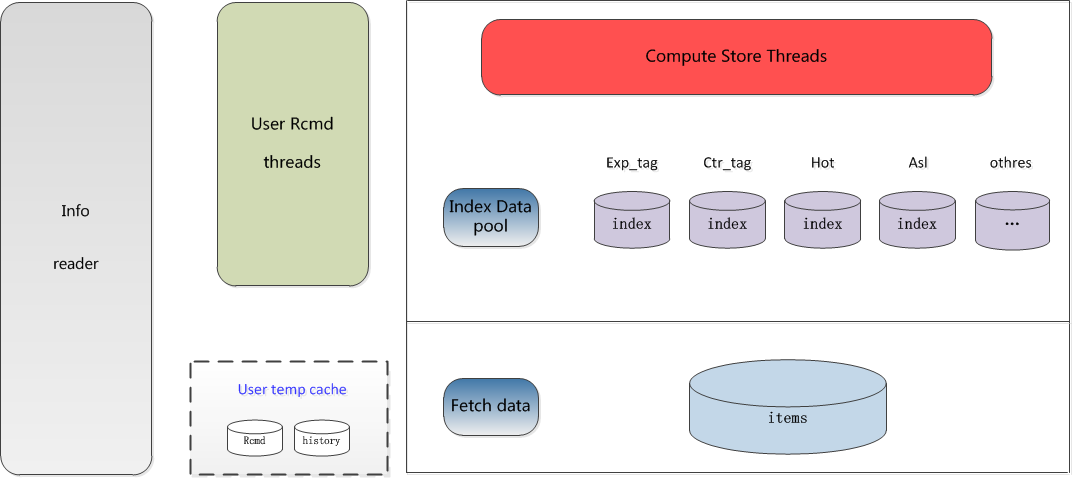
推荐数据查询优化
- 多个redis命令操作改为pipeline管道模式操作
- 一次计算多页推荐数据进行缓存
- 迭代器模式访问标签索引数据,控制游标的位置,在用户连续访问超过一定的时间后进行回位,保证查询最新的推荐数据。
- 多线程异步计算
查询设计图:
后记
头条信息对用户的价值关键在于推荐的算法,我们会根据大数据分析持续调整推荐算法、优化聚合算法,使用户的体验达到最佳。
作者介绍
方杰,微鲤后端研发主管,目前负责中华万年历、微鲤小说后端业务研发工作。曾作为主要研发人员参与中华万年历公众提醒、头条、生活圈等功能的开发。