单节点的统计系统
2014年之前,中华万年历统计的主要内容是广告,那时候统计方案是客户端采集到曝光、点击等数据,在客户端进行轻度汇总之后,提交到服务器,服务器通过redis做队列,采用Bitmap和Bitset的数据结构进行去重统计,然后快照到MySQL中,延时5分钟左右。这个阶段,运营和商务对于数据的需求是最简单的,对应每个广告每天的CTR指标即可,每天的广告数据量也比较小。该阶段的架构图如下所示:
 2014的年末,中华万年历中开始接入内容和社区,主要分为日视图卡片(信息流)和历知社区等两大核心模块,这个时候,内容量开始陡增,每天产生的用户浏览行为已经上升到一个我们此前从未企及的一个量级。这个时候,原有的统计系统显得力不从心了。
2014的年末,中华万年历中开始接入内容和社区,主要分为日视图卡片(信息流)和历知社区等两大核心模块,这个时候,内容量开始陡增,每天产生的用户浏览行为已经上升到一个我们此前从未企及的一个量级。这个时候,原有的统计系统显得力不从心了。
在这个时候,我们遇到的主要问题是数据处理速度太慢,当时的统计是单节点的,但是当时的每天的日志量超过100G,到了节日的时候,中华万年历的节日提醒功能,会唤起更多的用户,数据会更多,导致数据处理不过来,经常导致redis队列和统计的redis内存爆了,无法完成数据回滚,业务方抱怨不止。所以,我们首要任务是提高数据处理速度,想到最简单的方案就是扩节点,开始集群模式。
简单的集群模式
集群模式主要为了提高处理速度,我们主要针对计算模块进行扩展,其他地方保持不变。其整体的处理逻辑还是从redis中获取数据,在Java进程中进行处理,中间结果存放在redis中,然后定时将redis中的结果快照到MySQL中。 关于计算模块扩展,我们想到的最简单的方案是将统计的任务拆分为master和slave。slave可以多个,主要负责处理数据,将数据推入到redis中,各个进程通过redis共享中间结果。master定时从redis中将数据取出来,快照到MySQL中,业务方通过查询MySQL获取统计结果。架构调整如下图所示:
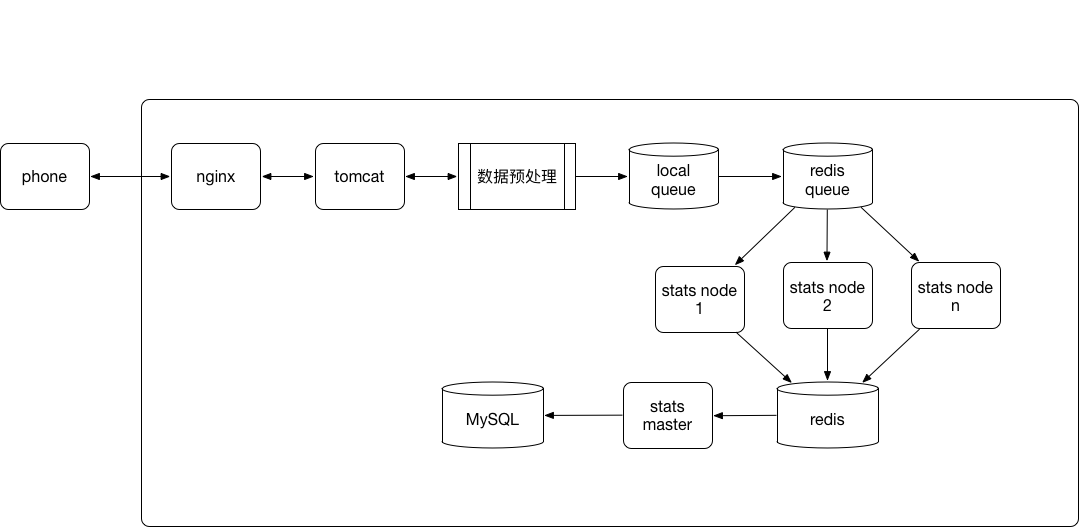
在此阶段,我们还对redis中数据结构做了调整。此前,我们通过Bitmap和Bitset来做uv的统计,中华万年历当时的装机量已经超过2.5亿,uid设计得比较大,单个Bitmap超过4M,我们线上的redis云服务器最大内存为64G,我们拆分为5台redis,并且均作了主从(共10个节点),所以的redis节点内存占用很高。此时我们在redis上遇到两个问题,第一redis内存碎片化严重;第二还有节日的时候,数据量大,redis内存占用非常高,常常导致bgsave无法完成,有时候主从同步无法进行。于是,解决redis内存问题也是一个方面,这个时候,redis已经支持HyperLogLog这样的近似计算的数据结构了,我们经过量化分析发现,虽然HyperLogLog有一定的误差率,但是误差率在我们可接受的范围内,毕竟日志统计也不需要严格精准,我们将统计的数据结构从Bitmap和Bitset更换为HyperLogLog,节省了大量的内存,而且不同的slave节点的操作是幂等的。内存碎片化主要是值长度差距大造成的,我们针对这一块也做了优化。
改进日志采集的简单集群模式
当处理速度不是问题的时候,其他的问题就凸显出来了,当时我们遇到节日的时候,中华万年历的节日提醒功能会唤起app,向服务器发起广告请求、信息流请求、日志提交请求。每到节日的10点中,并发非常高。由于后端tomcat负载很大,大量的请求在Nginx中无法成功转发,导致节日的时候,日活上升,但统计到的数据反而下降,业务处于不可用状态。这时需要迫切确定以及解决以下几个问题:
- 有哪些环节可以优化,提高客户端的提交的速度,减少数据的丢失?
- 数据到底丢失了多少?
首先,我们分析了日志的提交流程。日志的提交逻辑是,客户端提交nginx,nginx转发到tomcat,在tomcat需要进行参数验证、数据解密、反序列化、推入本地队列,然后再响应客户端。解密和反序列化都是非常消耗cpu的操作,而且需要占用一定的时间。这些占用的时间越长,nginx接受到的请求等待转发的时间越长,从而导致连接超时的概率增加,不仅仅影响提交采集数据,还影响广告和信息流的请求。我们可不可以将日志提交和业务拆分出来,让日志采集和广告系统分离开,互不影响。然后,对于参数验证、解密、反序列化没有有必要同步进行,完全放在后续异步处理。我们在采集的服务器最为重要的是保证提交的数据能够记录下来,不丢失即可。
其次,每天请求到nginx中,没有转发到tomcat的到底有多少?我们需要量化分析。我们做了两套方案,并行进行。第一种方案是维持原来的流程,在接口中进行参数验证、解密、反序列化等操作,每接受一次请求(不管请求是否合法),在redis中increment一次,类似kafka保存offset一样,然后每隔1秒钟,从redis中取出offset,将时间戳和offset写入日志。第二种方案是flume直接从nginx中采集访问日志,推入到kafka中,然后后面接入kafka的消费者,consumer每收到一条消息,也在redis中进行自增,然后将时间戳和当前的收到的消息数写入日志,也是1秒钟一次。我们按照每天和每小时的粒度,对比了两遍的offset的差值,结果发现一个惊人的数据,通过tomcat进行处理逻辑的比接nginx日志的,每天缺失15%的数据,节日的时候更多。
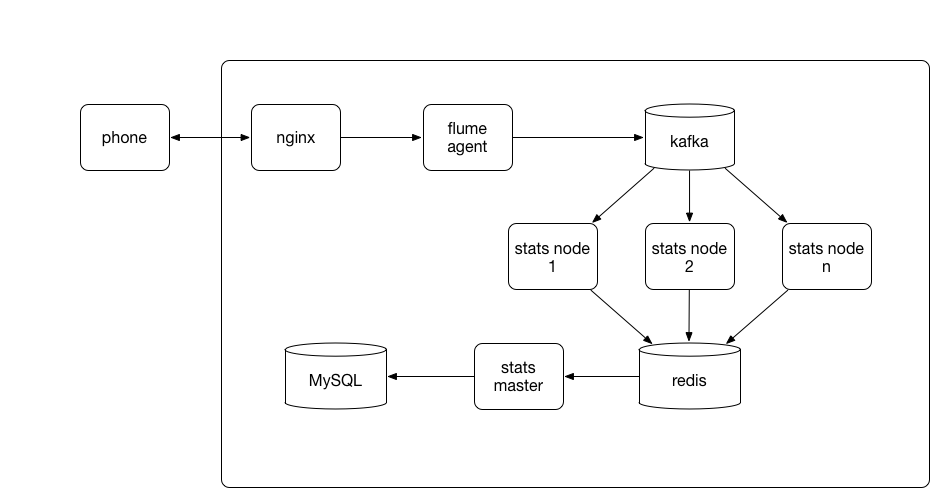
在分析问题的时候,我们逐步找到了解决方案。首先将日志采集服务器做成旁路,和其他业务分离,保证日志采集和其他业务互不影响。其次,去掉参数验证、解密、反序列化等同步操作,nginx接收到请求,直接打印日志,并且立即返回,去掉tomcat。然后通过flume agent将nginx日志tail到kafka中,将参数验证、解密、反序列化等放在kafka消费者中进行。整体架构图如下所示:
分布式计算和存储方案
经过前面的几个大版本的调整,统计系统稳定性,数据的可靠性提升很明显。但是,我们还是遇到了很多问题,主要集中在存储方案和计算方案上。
存储方案的问题
统计的结果和中间结果,存储在MySQL中,采取的按年分库,按照天和不同的业务模块进行分表。做报表的时候,查询需要跨表和跨库查询,SQL写起来非常复杂,而且效率不高。有些业务的数据在不同的库中,需要自己设计数据结构,在内存中做关联和倒排索引,代码写起来复杂,维护成本高。
随着数据量的上升,MySQL的读写性能也遇到了瓶颈。首先,我们在batch的大小、事务提交方案做了优化。其次,对于没有做主从的库,完成了主从,在主上写,从上面读。此外,还想通过表分区,优化MySQL的读时候IO性能,鉴于业界对于MySQL分区方案不太放心,最终放弃了。虽然花了不少时间去优化,但是终归是收效甚微。此时,对于我们来说,分布式的存储方案是我们最需要的。
统计中使用的Redis虽然在优化数据结构之后,节省了不少,但是毕竟使用的是内存,开销还是很大,对于创业公司来说,这仍然是一笔不小的开销,对于一些不需要支持OLTP业务的,我们希望能够从redis和MySQL中释放出来,寻求经济的存储方案。
计算框架的问题
当时,我们的没有分布式计算框架的支持,业务开发非常慢,需要处理很多非业务相关的逻辑,处理不好很容易出问题,对于开发非常不友好。stats node只能保证at most once,没有checkPointer机制,stats master还是一个单节点的,没有standby,master在写MySQL做快照的时候,由于MySQL写性能遇到瓶颈,导致了Full GC和内存溢出的情况。当时,业务方对于一些临时的需求比较多,这些需求都是离线的,而且只需要一两次,如果经过开发、发布的流程,一方面是时间太慢,另外一方面是开发代价太大。于是,我们想构建自己的数据仓库,能够支持即系查询。
解决方案
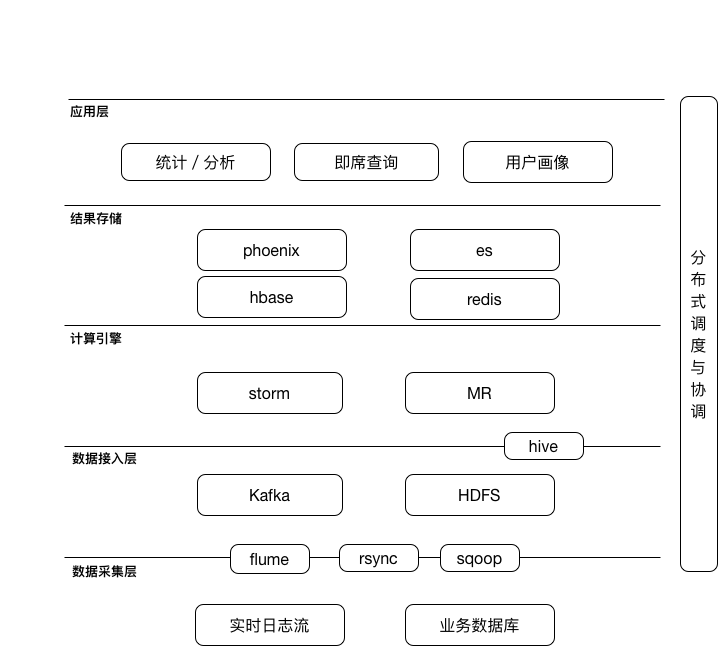
对于分布式计算,我们调研了Storm、Spark以及MapReduce(Hive)。首先排除了Spark,Spark采用scala开发,我们团队没有人熟悉这门语言,维护定位问题比较麻烦,此外,Spark streaming的实时性比不上Storm,满足不了当时一些特定的业务场景。其次,Storm和Hive使用的方案是最多的,解决方案也是最多的,而且我们对于Java和SQL也都很熟悉。而选择Hive的另外一个好处就是我们可以围绕它构建数据仓库,并且团队有成员对Hive非常熟悉,之前也阅读过源码。因此最终确定以Storm来做实时数据处理,Hive做离线数据处理。
对于分布式存储,我们选择了HBase以及基于HBase的Phoenix。选择HBase的原因是,HBase采用的LSM-tree结构,非常适合高频写操作,也适合和Storm对接,支持increment和TTL,方便做实时统计和数据的生命周期管理。对于部分业务数据比较少,需要通过SQL做一些逻辑的地方,我们采用的基于HBase的Phoenix。此外,我们选择了Hive来做数据仓库,在Hive的文件选择上,主要选择orcfile,只有在数据仓库的ods层部分特殊场景中采用了textfile。主要原因是orcfile的读写性能不错,支持列裁剪。基于Hadoop,我们还使用hue为数据分析师提供了即席查询功能。
此外,我们将原始日志定期备份到HDFS上,在出现故障时能够离线进行数据回滚、重新计算。并使用azkaban作为分布式调度与协调服务,管理所有离线任务的定期或者单次执行。
与此同时,除了数据统计的业务,我们开始了诸如用户画像构建、信息流模块中的内容淘汰等业务,相比起来,这些业务要求的实时性更高,需要支持OLTP业务。因此,这一部分数据我们选择存储在Redis中。而对于复杂多维度的查询,我们则通过ES来实现。这时的整体架构如下图:
当前的情况
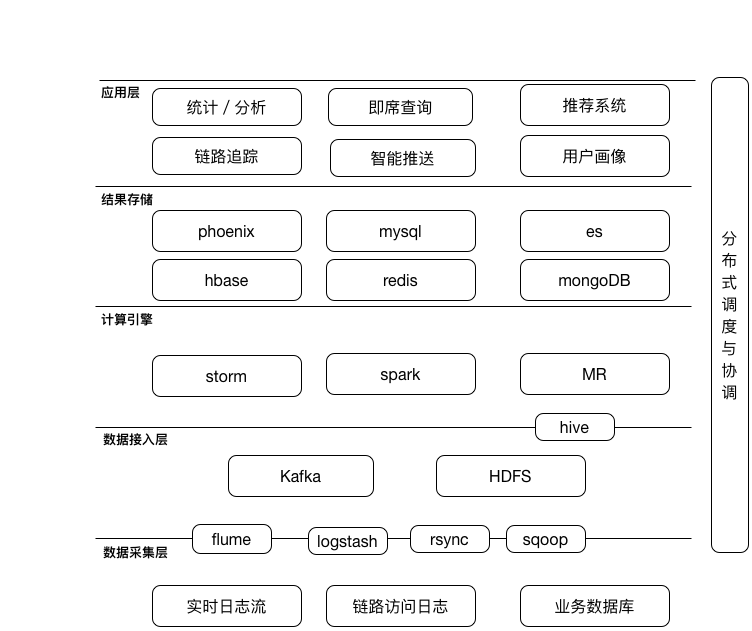
在App的统计、分析支持得到认可的情况下,公司对于数据驱动的业务需求越来越多。如:万年历中的信息流内容推荐;运维团队希望借助大数据方案来对核心的接口做调用链路还原、监控和响应时长分析统计,即一套链路追踪系统;运营团队希望根据用户的活跃和浏览行为,能够对用户进行个性化的推送,提高用户的留存和使用时长。
为了满足业务的需求,我们逐步引入了一些新的技术方案,比如Spark:一方面Spark MLib用来做机器学习,完成自己的推荐系统; 另一方面,我们发现yarn的资源利用率不高,但Storm集群资源紧张,而对于部分业务来说对于实时性的要求并不高,可以接受分钟级别的延迟,因此引入Spark streaming来完成这些业务。此外,我们对于一些不太合适的技术方案也在考虑进行替换。比如:我们发现flume agent每启动一个实例,需要单独占用一个cpu,社区反馈这是一个bug,新版本中没有解决这个问题,而与此同时,公司正在引入ELK进行集中式日志管理,得到了不错的效果,于是我们正在逐步用ELK中的logstash替换flume。经过这些调整之后,随身云大数据平台目前的整体架构如下所示:
总结
本文介绍了随身云大数据平台从无到有的过程。简单的介绍了各个阶段遇到的主要问题,以及我们的解决方案。虽然还有很多不完善的地方,但是希望把自己的一些经验分享出来,和大家共同探讨,也希望大家能够提供一些意见和建议。文中没有做更多的技术细节的描述,关于更多的技术细节,在后续的文章中会进行专项的描述。
作者介绍
黄骞,随身云资深后端开发工程师。作为核心开发人员参与了随身云大数据平台、广告平台、智能推送平台等系统的开发与设计工作。