文章记录了项目中遇到的一个线上问题--线上服务持续Full GC,最终定位到是 ThreadLocal 在线程池场景下的内存泄漏。问题本身不复杂,但排查过程中涉及到 JVM 内存模型、GC 机制、ThreadLocal 底层实现、线程池源码等多个知识点。
1. 背景
那天是个周末,我照例做生产环境巡检,打开监控大盘一看,bill 服务的 GC 指标不太对劲——Full GC 的频率明显升高,而且看趋势没有收敛的迹象。
虽说 Full GC 偶尔出现一两次也不算什么大事,但连续触发就不正常了。于是我把 GC 日志捞了下来,丢到 GCeasy 上做了一次分析。
GC 日志分析
GCeasy 的分析结果非常直观——老年代(Old Generation)的内存使用量一直在爬坡,从大约 300MB 稳步上升到接近 500MB,before GC 和 after GC 的曲线几乎是贴着往上走的,GC 回收后的内存基本没怎么释放。
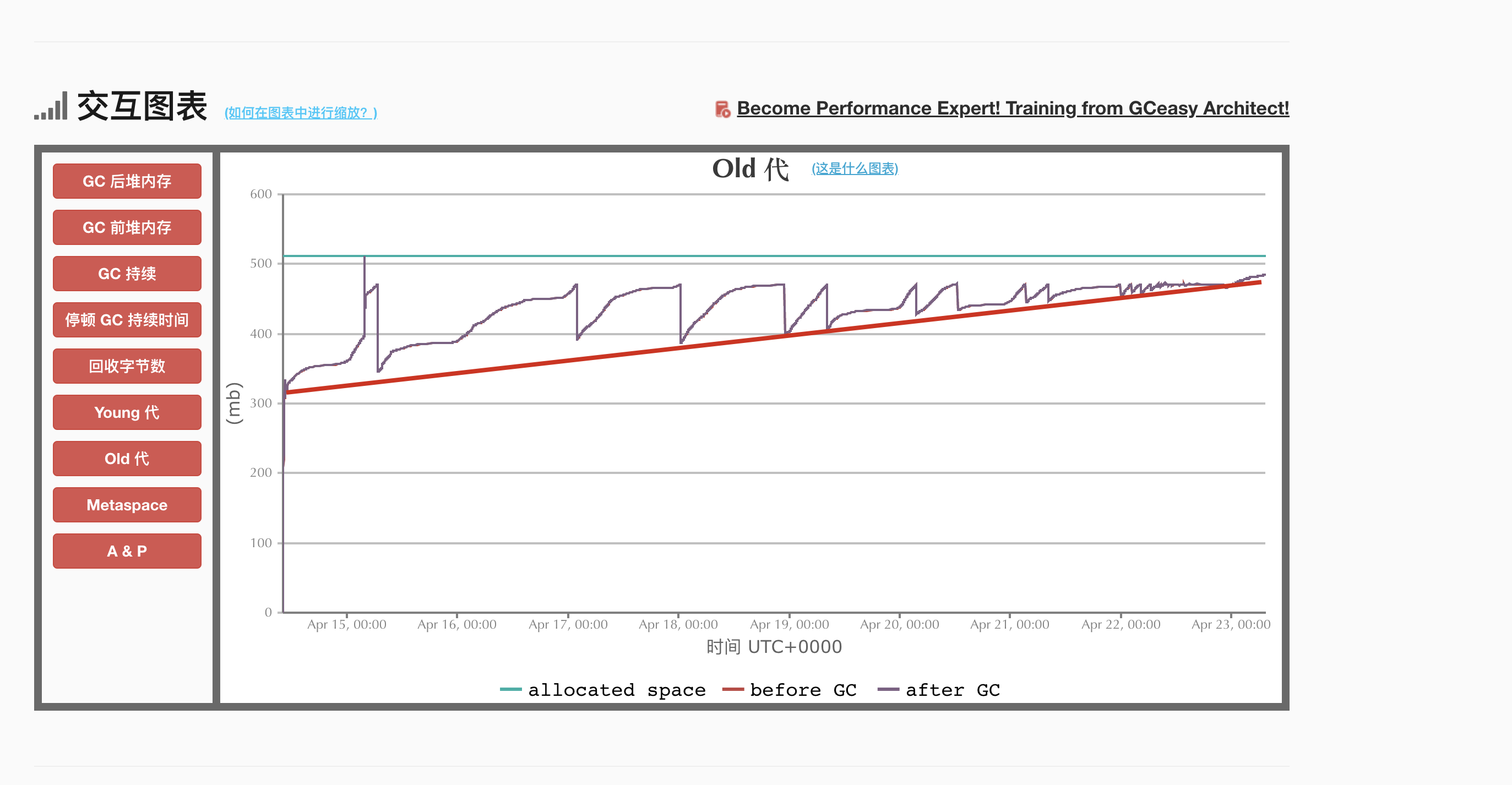 这条平稳上升的曲线,几乎就是内存泄漏的标志性特征。
这条平稳上升的曲线,几乎就是内存泄漏的标志性特征。
简单解释一下这里的判断依据:正常情况下,Full GC 之后老年代的内存应该会有明显下降(因为不再被引用的对象被回收了)。但如果 GC 后内存几乎不降,说明老年代里有大量对象仍然被强引用持有,GC 想回收但回收不了——这就是典型的内存泄漏表现。
为什么是老年代?
这里顺便聊一下 JVM 的分代模型。在 HotSpot JVM 中,堆内存分为年轻代和老年代:
年轻代(Young Generation):新创建的对象优先分配在这里,经过若干次 Minor GC 仍然存活的对象会被晋升到老年代
老年代(Old Generation):存放长期存活的对象,Full GC 时才会被回收
泄漏对象之所以最终堆积在老年代,是因为它们一直被引用,每次 Minor GC 都无法回收,年龄不断增长直到晋升。一旦大量泄漏对象进入老年代,就会导致老年代空间不断被挤占,最终触发 Full GC。而 Full GC 又回收不了这些对象,就形成了频繁 Full GC 的恶性循环。
2. 堆转储分析:MAT 定位泄漏源
既然怀疑是内存泄漏,那就得上 heap dump + MAT(Eclipse Memory Analyzer Tool)了。
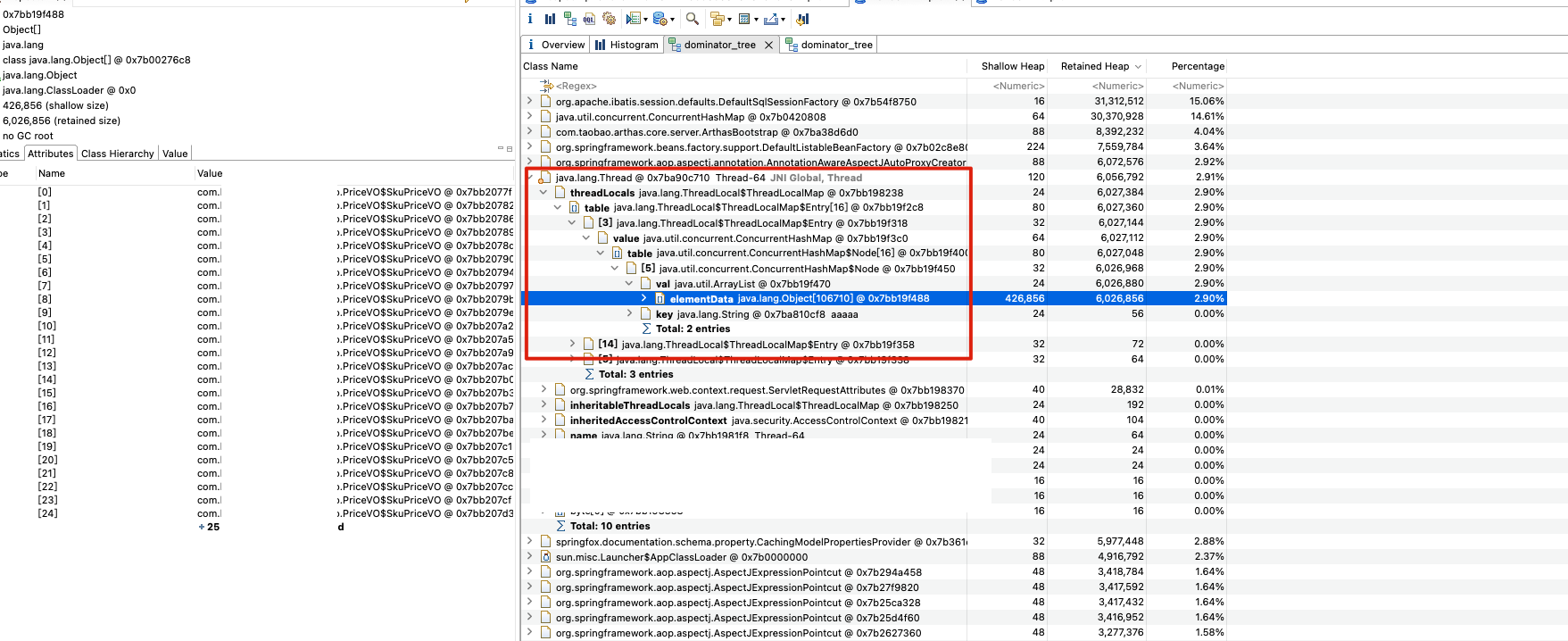
我在生产环境 dump 了一份堆快照文件(.hprof),用 MAT 打开后,先看了一眼 Dominator Tree(支配树)。结果一目了然:排在前面的几个线程对象,每个都持有了大量的 PriceVO$SkuPriceVO对象,而且这些对象全部挂在 ThreadLocal 上。
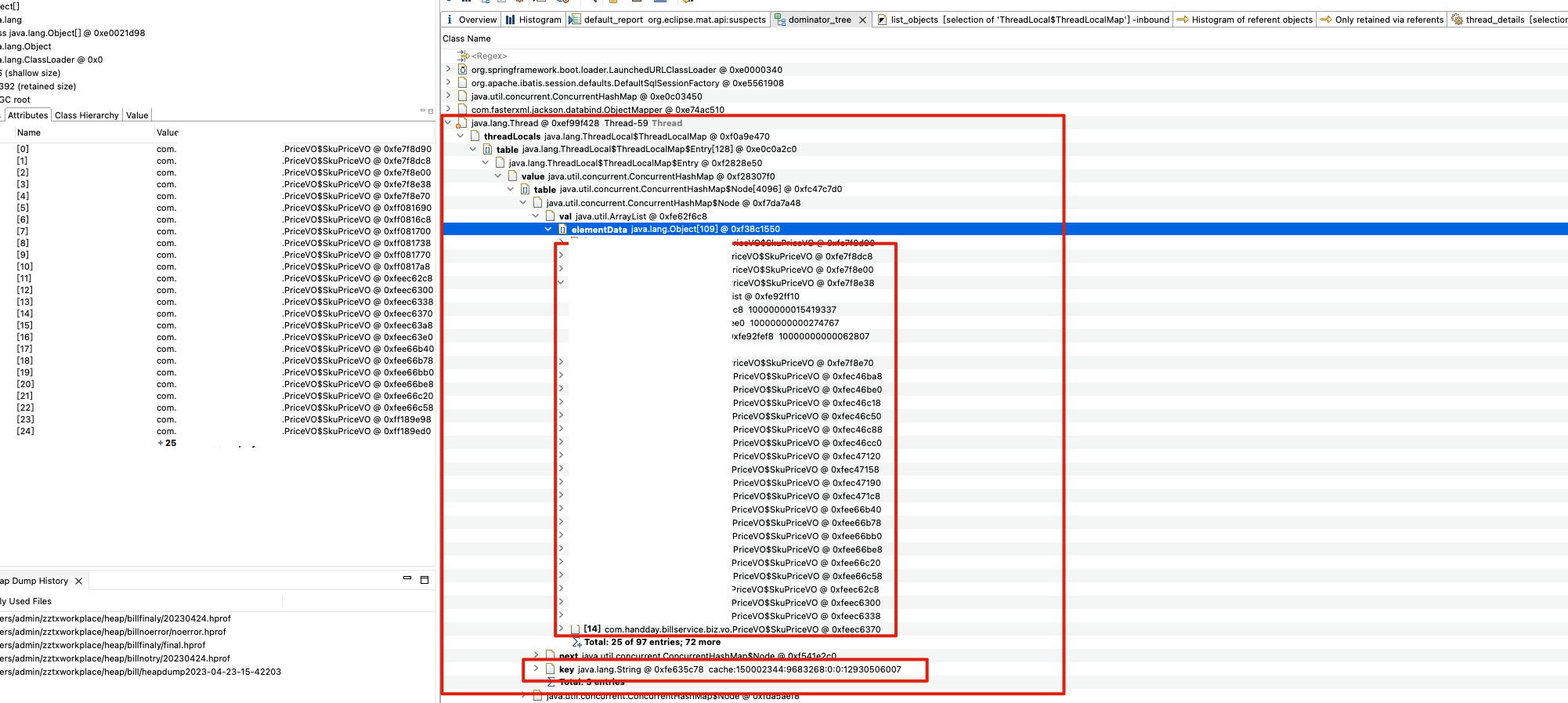 展开其中一个线程的引用链:
展开其中一个线程的引用链:
java.lang.Thread
└── threadLocals: java.lang.ThreadLocal$ThreadLocalMap
└── table: java.lang.ThreadLocal$ThreadLocalMap$Entry[]
└── [n]: Entry
└── value: java.util.concurrent.ConcurrentHashMap
└── key: String (cacheKey)
└── value: List<PriceVO.SkuPriceVO> // 大量泄漏对象
到这里,问题的轮廓已经很清晰了:ThreadLocal 中缓存的对象没有被及时清理,随着请求的不断到来,缓存数据越积越多,最终导致内存泄漏。
ThreadLocal 为什么容易泄漏?
这里有必要深入聊一下 ThreadLocal 的内存模型。
每个 Thread对象内部都维护了一个 ThreadLocalMap,它是一个以 ThreadLocal实例为 key、以实际存储值为 value 的散列表。特别的是,key 是一个 弱引用(WeakReference),但 value 是 强引用。
Thread
└── ThreadLocal.ThreadLocalMap threadLocals
└── Entry[] table
└── Entry extends WeakReference<ThreadLocal<?>>
key → ThreadLocal 实例 (弱引用)
value → 实际存储的对象 (强引用)
在普通场景下(每个请求一个线程,用完即销毁),ThreadLocal 不会有什么问题,因为线程死亡后整个ThreadLocalMap都会被 GC 回收。
但在线程池场景下就不一样了。线程池中的线程是复用的,一个线程处理完一个任务后不会被销毁,而是继续等待下一个任务。这意味着线程对象一直存活,它内部的ThreadLocalMap也一直存活,value 就永远不会被回收。
如果每次任务执行时都往 ThreadLocal 里塞数据,但执行完后又不清理,那这些数据就会一直在线程的 ThreadLocalMap里面累积,直到把内存撑爆——这就是经典的 ThreadLocal + 线程池内存泄漏模式。
3. 代码审查:找到写入点和"形同虚设"的清理逻辑
接下来就是 review 代码了。很快就找到了数据写入 ThreadLocal 的地方——在一个价格过滤方法中:
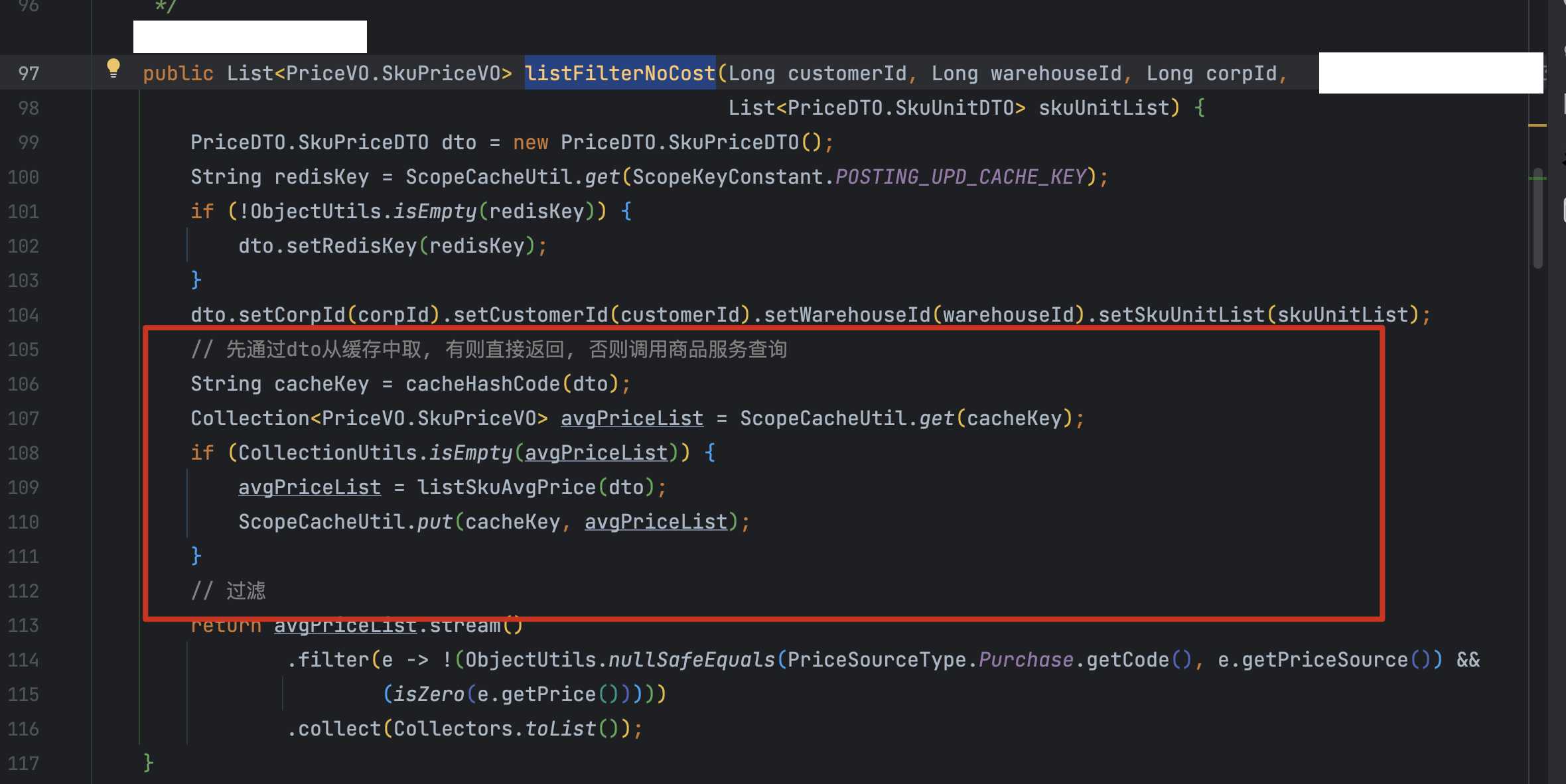 关键逻辑如下:
关键逻辑如下:
public List<PriceVO.SkuPriceVO> listFilterNoCost(Long customerId, Long warehouseId,
Long corpId, List<...> skuUnitList) {
// 先从 ThreadLocal 缓存中取,有则直接返回
String cacheKey = cacheHashCode(dto);
Collection<PriceVO.SkuPriceVO> avgPriceList = ScopeCacheUtil.get(cacheKey);
if (CollectionUtils.isEmpty(avgPriceList)) {
avgPriceList = listSkuAvgPrice(dto);
ScopeCacheUtil.put(cacheKey, avgPriceList); // 写入 ThreadLocal
}
// ... 过滤逻辑
}
这段代码的意图是用 ThreadLocal 做一个"请求级别"的本地缓存——同一个请求内,相同参数的价格查询结果缓存起来,避免重复调用下游服务。思路没问题,但必须在任务执行完后清理掉。
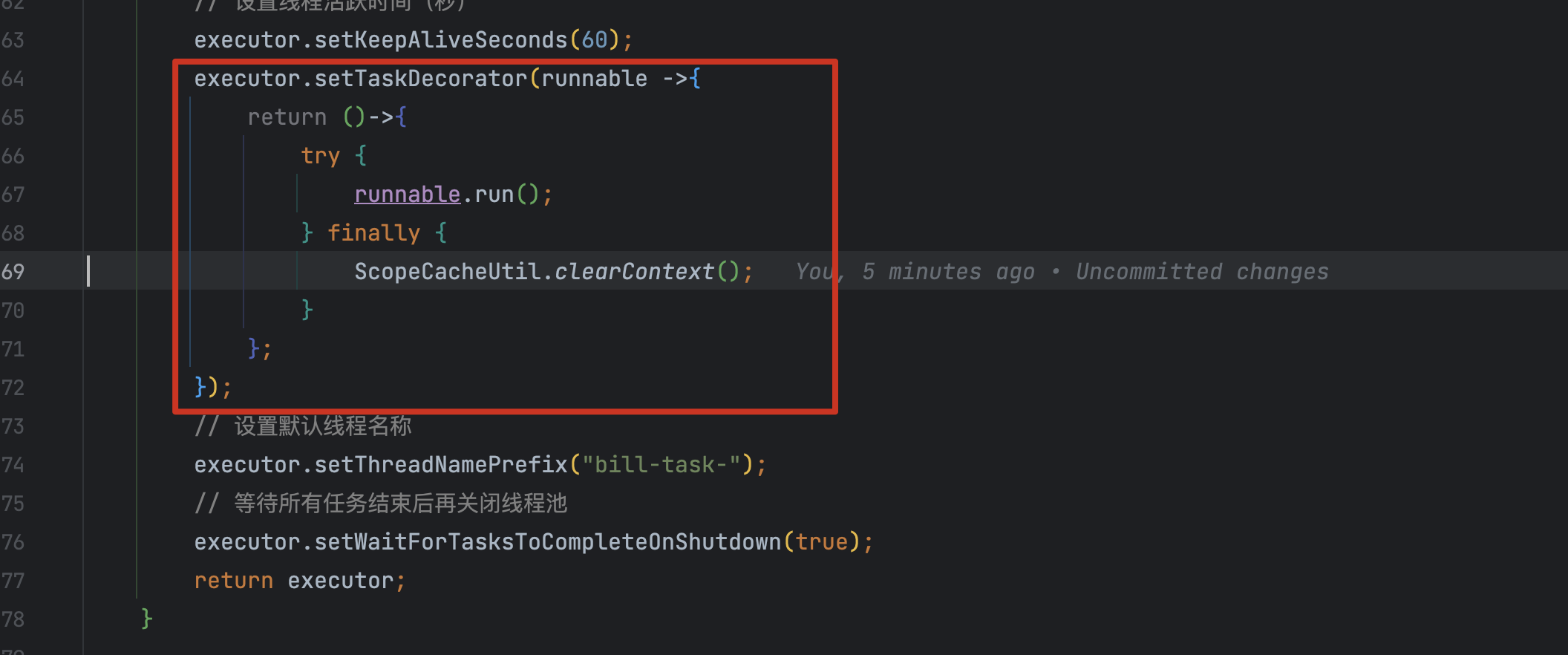
然后我找到了线程池的配置代码,发现确实有清理 ThreadLocal 的逻辑:
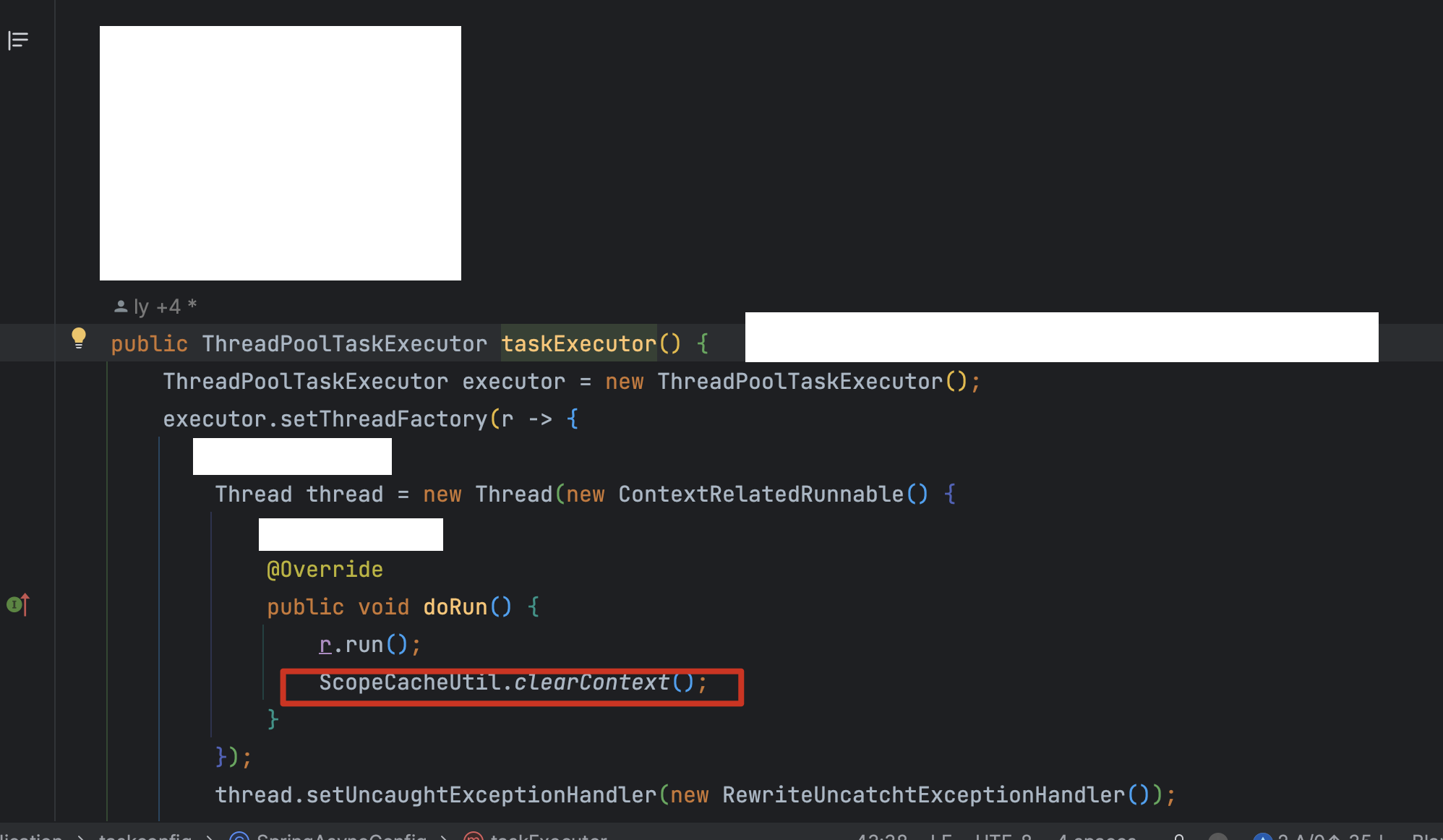 核心配置代码:
核心配置代码:
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setThreadFactory(r -> {
Thread thread = new Thread(new ContextRelatedRunnable() {
@Override
public void doRun() {
r.run();
ScopeCacheUtil.clearContext(); // 清理 ThreadLocal
}
});
// ...
return thread;
});
return executor;
}
看起来没啥问题对吧?在doRun()方法里,先执行任务r.run(),然后调用 ScopeCacheUtil.clearContext()清理。
但我在本地加了断点调试后发现——clearContext()这行代码根本就没执行过!
本地 MAT 分析也验证了这一点,ThreadLocal 中的对象依然在不断累积:
4. 根因分析:ThreadFactory 中的 r 到底是什么?
这就是整个问题最有意思的地方了。
调试时我仔细看了一下 setThreadFactory(r -> { ... })中这个参数 r 的运行时类型,发现它不是我们提交的业务 Runnable,而是 java.util.concurrent.ThreadPoolExecutor$Worker对象。
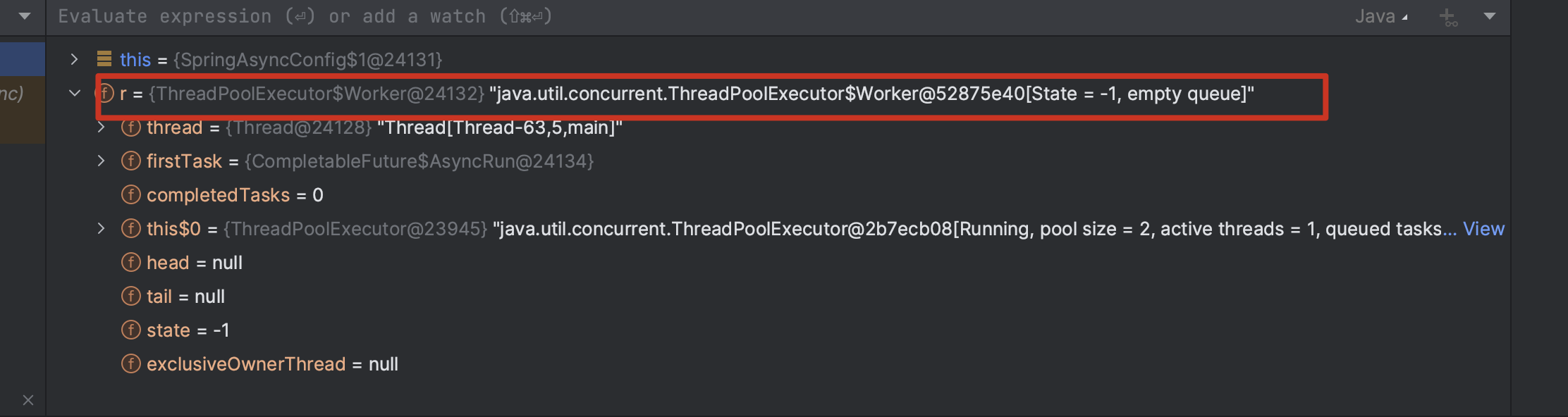
r = {ThreadPoolExecutor$Worker@24132}
"java.util.concurrent.ThreadPoolExecutor$Worker@52875e40[State = -1, empty queue]"
这下一切都说得通了。
线程池的内部运作机制
要理解这个问题,需要了解 ThreadPoolExecutor的核心机制。线程池内部有一个 Worker 类:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread;
Runnable firstTask;
public void run() {
runWorker(this);
}
}
Worker本身就是一个 Runnable。 当线程池需要创建新线程时,会通过 ThreadFactory.newThread(Runnable r)创建线程,但这里传入的r不是用户提交的任务,而是Worker对象本身。
Worker.run()方法内部调用 runWorker(this),这是一个循环——它会不断地从任务队列中取出任务并执行。换句话说,Worker是线程的"引擎",它的
run()方法在线程存活期间几乎不会返回(除非线程池关闭或线程被回收)。
所以原来代码中的清理逻辑:
r.run(); // Worker.run() → runWorker() 循环
ScopeCacheUtil.clearContext(); // 几乎永远不会执行到这里!
r.run()就是启动了 Worker 的工作循环,这个循环会一直跑下去,clearContext()在后面等着,但永远轮不到它执行。就好比你在一个死循环后面写了一行代码——编译器不报错,但它就是跑不到。
这也是为什么这个 bug 隐藏了这么久:代码看起来逻辑完整,清理操作确实写了,但就是不生效。
5. 解决方案:使用 TaskDecorator
找到了根因,修复方案也就明确了。我们需要的是在每个任务执行前后做 hook,而不是在线程创建时做 hook。
Spring 的ThreadPoolTaskExecutor提供了一个非常优雅的扩展点——TaskDecorator。它的作用是对提交到线程池的每一个任务进行装饰(包装),可以在任务执行前后添加自定义逻辑:
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setThreadFactory(r -> {
Thread thread = new Thread(new ContextRelatedRunnable() {
@Override
public void doRun() {
r.run();
ScopeCacheUtil.clearContext(); // 清理 ThreadLocal
}
});
// ...
return thread;
});
return executor;
}
这里用了 Java 8 的 Lambda 语法,本质上就是返回一个新的Runnable,它在 finally 块中确保无论任务正常完成还是抛出异常,都会执行 clearContext()清理 ThreadLocal。
调试验证:使用TaskDecorator 后,runnable参数的运行时类型是 CompletableFuture$AsyncRun——这才是我们真正的业务任务对象。每个任务执行完成后,finally块都能正确执行,ThreadLocal 被及时清理,内存不再泄漏。
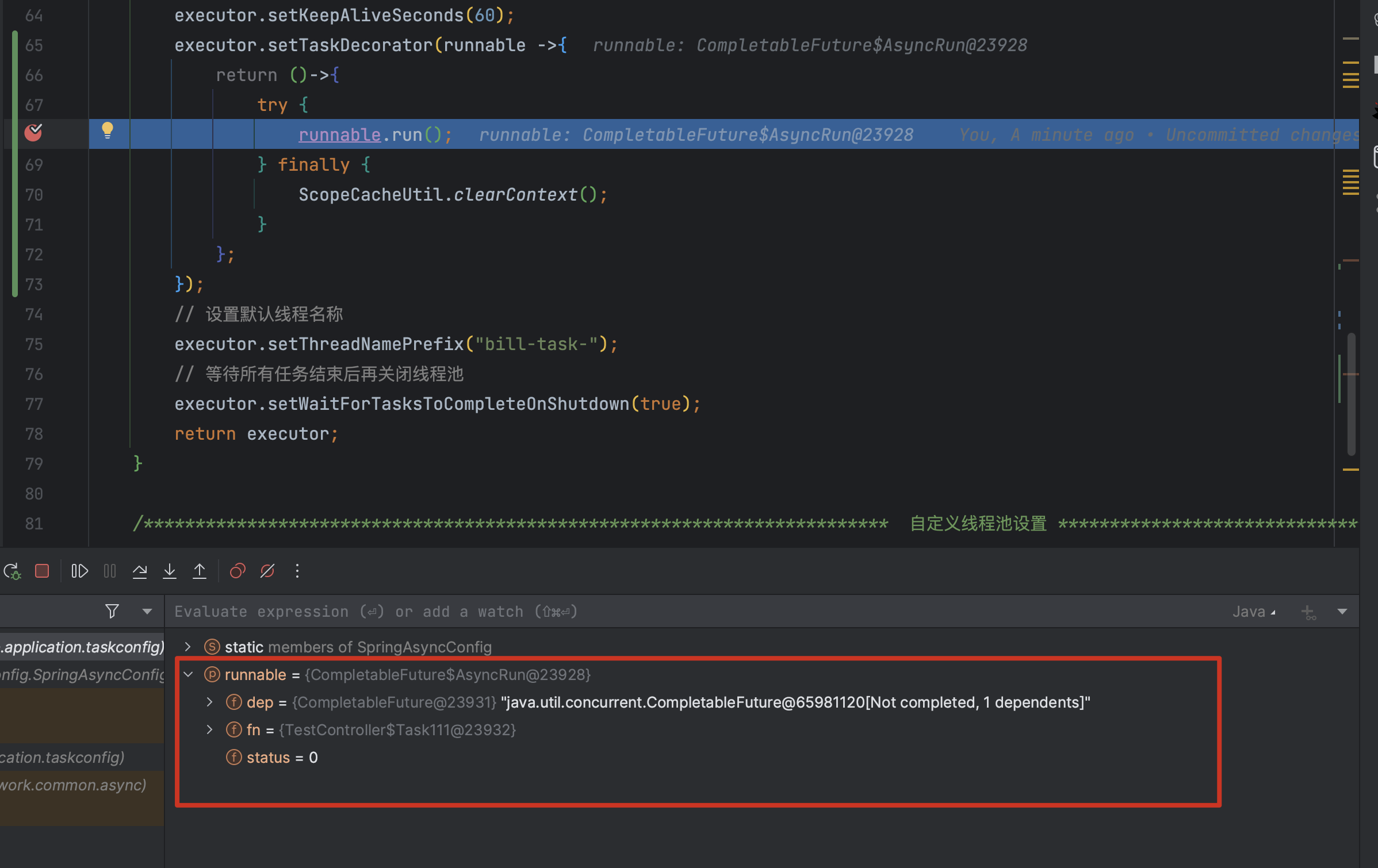 把原来
把原来 ThreadFactory 中无效的清理代码删掉,只保留 TaskDecorator 的方案,修复完成。
6. 延伸思考
6.1 ThreadFactory vs TaskDecorator:职责边界
这个 bug 的本质其实是混淆了 ThreadFactory 和 TaskDecorator 的职责:
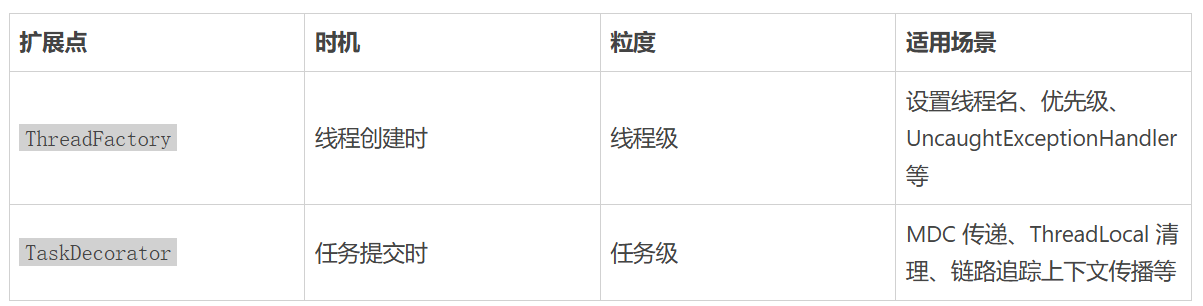 一句话总结:线程级别的设置用 ThreadFactory,任务级别的 hook 用 TaskDecorator。
一句话总结:线程级别的设置用 ThreadFactory,任务级别的 hook 用 TaskDecorator。
6.2 ThreadLocal 使用的最佳实践
经过这次踩坑,我总结了几条在线程池场景下使用 ThreadLocal 的原则:
1.用完必清理:在 finally块中调用 ThreadLocal.remove(),就像用完数据库连接要关闭一样
2.优先用 TaskDecorator 兜底:即使业务代码里写了remove(),线程池层面也加一层保险
3.考虑替代方案:如果只是想在一个调用链中传递数据,可以考虑用方法参数显式传递,或者使用TransmittableThreadLocal(阿里开源)来解决跨线程池传递的问题
4.监控 + 巡检:定期关注 GC 日志和堆内存趋势,早发现早处理
6.3 排查内存泄漏的通用思路
最后梳理一下排查内存泄漏的一般套路,权当留个备忘:
1. 发现异常
└── 监控告警 / 巡检发现 Full GC 频繁
2. 确认泄漏
└── 分析 GC 日志(GCeasy / GCViewer)
└── 观察 Old 代内存趋势:GC 后是否回落
3. 定位泄漏对象
└── jmap -dump 导出堆快照
└── MAT 分析:Leak Suspects / Dominator Tree / Histogram
└── 找到占用内存最大的对象及其 GC Root 引用链
4. 代码审查
└── 根据引用链找到代码中的写入点
└── 检查是否有清理逻辑,清理逻辑是否真的生效
5. 修复 & 验证
└── 本地复现 + 断点调试
└── 修复后观察内存趋势是否恢复正常
7. 总结
回过头看,这个问题的直接原因很简单——ThreadLocal 没清理导致内存泄漏。但真正有意思的是:代码里明明写了清理逻辑,看着完全没问题,实际上却从来没执行过。
这也是线上问题排查中常见的一种情况:不是没做,而是做了但没生效。写代码容易,验证它真的按预期工作,才是更重要的事。
如果你也在用线程池 + ThreadLocal 的组合,建议检查一下你的清理逻辑到底挂在了 ThreadFactory 还是 TaskDecorator 上——别让你的清理代码也成了"永远跑不到的那一行"。
作者介绍:
- 唐武 高级服务端开发工程师