背景
- 在任何一个生产产品的行业,不管是互联网行业,还是建筑行业,或者是医疗行业,都得面对一个事物,那就是故障;
- 故障处理的好,那只是一个故障;故障处理的不好,就有可能升级成不同级别的事故;
- 出现事故,这是任何人都不想看见的;
- 如何避免事故,是安全生产的头等大事;
- 在这里,我会介绍我们公司的一些安全生产及故障管理的实践,大概分如下几部分:
- 故障前;
- 故障中;
- 故障后;
- 故障处理流程图;
- 事故管理制度;
- 可用率保障小组。
故障前
既然是故障前,说明故障还未发生,那故障前的关键工作包含以下几点:
- 隐患分析及修复;
- 故障预警;
- 预警响应。
隐患分析及修复
- 隐患分析目的:分析清楚自身系统的隐患,才能知道可能的风险以及如何应对;
- 隐患分析方法及工具:FMEA方法,排除架构可用性隐患的利器,引用自《从零开始学习架构》;
- 结合自身实际情况梳理隐患表,以下是我们结合实际情况,针对技术基础设施redis,输出的隐患分析demo。
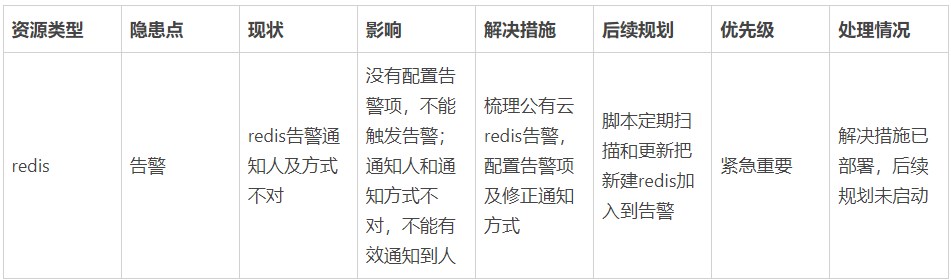 - 隐患修复:
- 目的:修复隐患,提高系统的可用性、可扩展性、可维护性;
- 方法及工具:
- 根据优先级安排修复任务排期;
- 持续跟进任务进度,形成闭环。
- 隐患分析并非一劳永逸,需要按周期持续迭代及优化。
- 隐患修复:
- 目的:修复隐患,提高系统的可用性、可扩展性、可维护性;
- 方法及工具:
- 根据优先级安排修复任务排期;
- 持续跟进任务进度,形成闭环。
- 隐患分析并非一劳永逸,需要按周期持续迭代及优化。
故障预警
- 故障预警的核心工作是完善监控告警体系,这也是一个专题工作及实践;
- 这里提出2个问题及思考:
- 思考1:故障前,说明故障还未发生,但是为啥最终故障发生了(针对缓慢触发型告警)?
- 缓慢触发型告警:告警不是突发性触发的告警,告警对应指标的值是缓慢增长到告警阈值,触发的故障时可以避免的;
- 故障原因:
- 监控告警有没有配置:覆盖率是否100%?监控告警覆盖对象有没有被自动化添加到告警对象中?
- 监控告警覆盖维度是否全面?常见的维度(指标、日志、trace),需要整个业务研发团队一起完善,需要对自己负责的系统做好监控告警;
- 告警触发方式是否完善?阈值告警(count)、斜率告警(pdiff)等;
- 监控告警有无触发验证?配置了告警,但没有验证过,往往会失效;
- 故障处理是否闭环?星星之火,可以燎原,故障处理要像灭火一样处理干净。
- 优化措施:
- 完善监控告警体系。
- 思考2:完善了监控告警,就不会有故障了?
- 突发型触发告警:告警是突发性触发的告警,告警对应指标的值是一下子增长到告警阈值,触发的故障较难避免;
- 故障原因:
- 有变更:有发布或重启服务、有变更配置、外部依赖有变更、有服务被关闭或下线等;
- 有突发流量:有推广活动、受到外部或自身原因引起的DDOS攻击等;
- 优化措施:
- 不要轻视线上变更(有可能触发研发高压线及严重事故);
- 完善操作sop及应急预案。
预警响应
- 预警响应有两个关键点:
- 告警方式能否有效通知到处理人?
- 故障处理是否及时?如果不及时处理,故障可能升级成事故;
- 告警方式怎么有效通知到处理人?
- 确保重要告警,使用电话告警,电话、短信、邮件的通知到人的有效性不一样,电话最高;
- 确保告警接受人能正常接收到告警(手机需要保持非静音、有电、有信号);
- 确保告警有升级策略,避免因为一个人没响应,告警没有备份处理人处理的情况;
- 故障怎么能被及时处理?
- 处理故障处理流程,按SOP操作;
- 梳理故障应急预案,做好演练;
- 保障工具良好运行,避免一到处理故障,就出现各种异常情况(无网络、vpn失效、电脑死机、家用电脑和工作电脑环境不一致等);
- 设定告警响应OKR,比如一个OKR周期内,0.3分标准为告警未及时响应次数《2(根据团队具体人数及情况而定)。
故障中
- 既然是故障中,说明故障已经发生,那故障中的关键工作包含以下几点:
- 故障信息同步:
- 找人、确认所有影响、服务恢复方案和预计恢复时间;
- 故障处理方案同步;
- 故障处理
- 止损、保留现场;
- 恢复服务;
- 故障恢复信息同步;
- 故障升级;
故障后
- 既然是故障后,说明故障已经修复,那故障后的关键工作包含以下几点:
- 故障报告
- 事故描述
- 事故解决方案
- 事故原因分析
- 事故影响
- 后续如何避免
- 事故收尾工作
- 问题是否切底解决
- 未解决,有解决方案:追踪和解决问题(建任务),形成闭环。
- 未解决,没有根治方案:完善预防监控措施。
故障处理流程图
- 根据以上的“故障前、故障中、故障后”总结出微鲤故障处理流程图,SOP如下图,具体情况,还需具体分析。
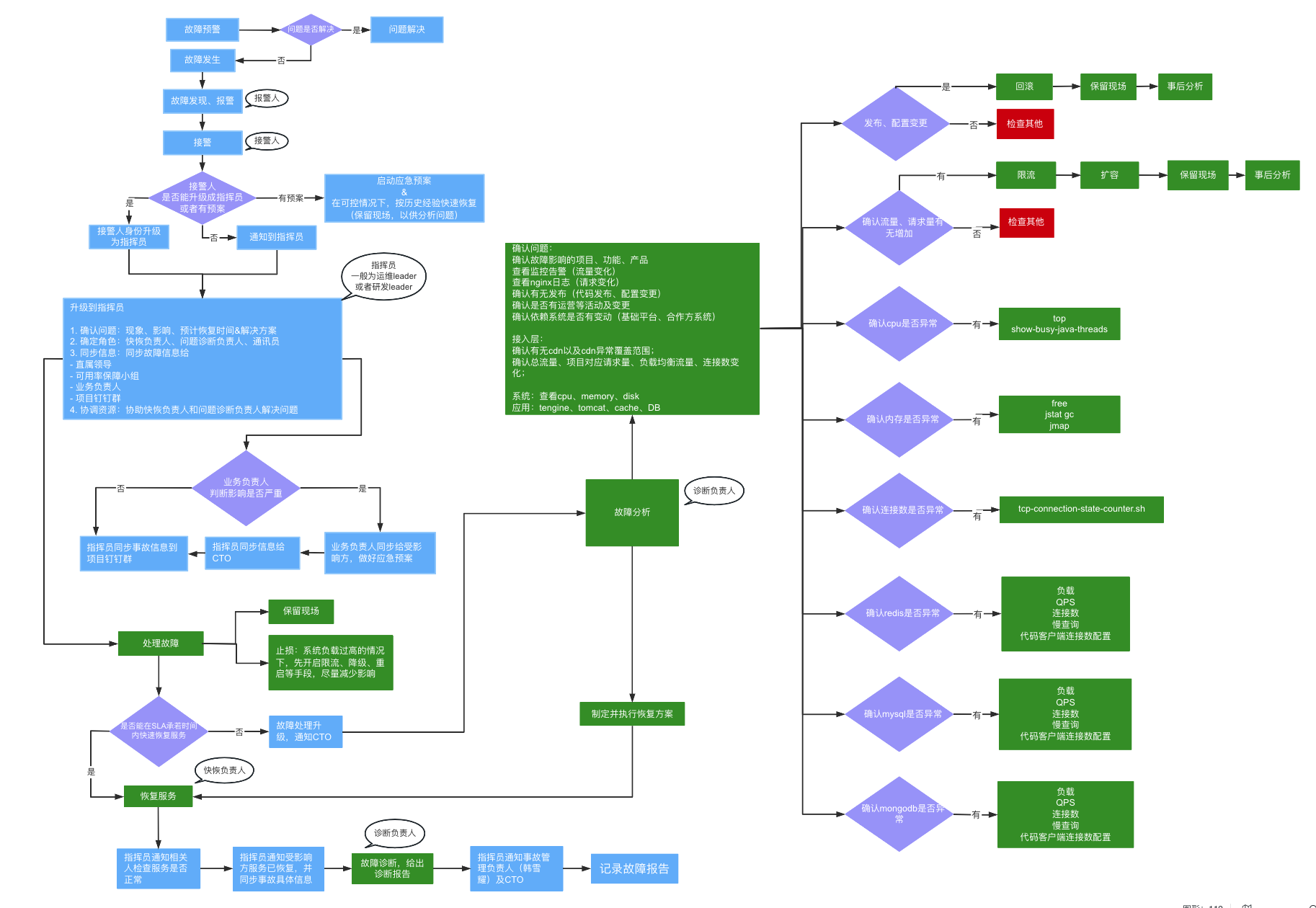
- 故障处理流程图中的关键角色:
- 报警人:反馈故障的人;
- 接警人:接到故障反馈的人;
- 指挥员:故障处理全局协调人;
- 快恢负责人:能够快速恢复故障,止损的人;
- 诊断负责人:诊断故障原因,给出解决方案的人。
事故管理制度
- 目的:出了故障后,我们需要上报故障,看故障是否升级为事故,并进行事故管理,所以需要建立对应的事故管理制度。
- 事故管理制度关键工作包含以下几点:
- 确定事故管理负责人:
- 跟进事故记录;
- 跟进事故定级和定责;
- 跟进事故处理和总结;
- 每月发送事故月报到部门负责人;
- 事故定级,根据对业务影响情况定级;
- 事故定责,根据需要改进的地方定责;
- 制定事故记录模板:
- 事故等级
- 事故时间以及发现人
- 事故现象
- 事故影响
- 事故解决方案
- 事故原因
- 后续改进
- 制定事故处理红线:出现事故后必须同步信息至业务负责人,为了避免扩大损失快速处理的同时,处理流程及事故信息需同步公开,不得私自修复后隐瞒;
- 制定研发高压线:需要定义清楚未经授权或确认,私自进行会触发事故的高危操作,根据企业具体情况制定。
- 确定事故管理负责人:
可用率保障小组
- 目的:
- 从全方位提高每个业务的可用率;
- 基于微鲤事故管理机制,我们出了事故后,事故管理存在定责的环节,这中间可能存在定责不清的情况,为了优化这种情况,所以建立了可用率保障小组及机制。
- 机制
- 每个业务团队,组建一个可用率保障小组;
- 可用率保障小组成员由研发、测试、运维共同组成;
- 业务可用率由可用率保障小组部分或全部成员保障;
- 故障定责机制:
- 责任方无异议,遵循事故管理机制责任划分;
- 业务方需要对业务可用率做好监控告警,因业务方不清楚自己负责业务的可用率导致的故障由业务方负主责(目的:推进业务方关注自己的业务可用性);
- 每个业务方需要对自己负责的业务系统的可用性、可用率负责;
- 如果有支撑方,业务方需要告知支撑方隐患点以及需要支撑方做什么来保障可用性;
- 业务方需要给出自己的承若及SLA;
- 需求方和支撑方都可以给对方提出高可用优化建议,如果技术委员会认定可执行但没有执行,引起的故障为未执行建议方主责;
- 引起故障的原因都不在双方的隐患分析里面,且故障定责有异议,则双方共同承担主责。
总结
- 以上是我们在故障管理方面的实践经验,主要就是故障管理三部曲以及其他一些实践,包括故障前、故障中、故障后、故障处理流程图、事故管理制度、可用率保障小组等方面实践;
- 我们可以根据我们具体情况,具体分析,持续优化故障管理,达到减少故障、避免故障、减少业务损失的目的。
作者介绍
- 邹永红 高级SRE专家