1、背景
在业务发展初期,数据量较少,统计需求也较少。基于成本考虑,EMR集群规模为1个master主节点+3个核心节点。
主节点负责管理集群,它通过运行软件组件来协调在其它节点之间分配数据和任务的过程以便进行处理。主节点跟踪任务的状态并监控集群的运行状况。
核心节点具有运行任务并在集群上的 Hadoop Distributed File System(HDFS)中存储数据的软件组件,主要负责任务的执行和数据的存储。
随着业务的发展,单master节点的集群存在越来越高的高可用风险,一旦master节点出现故障宕机,那么整个EMR集群都将不可用。必须要对EMR集群进行高可用技术方案升级。
2、为什么升级
随着业务的发展,单master节点的集群存在越来越高的高可用风险,具体如下:
1、master节点一旦宕机,则整个EMR集群将进入不可用状态。
2、master节点上有HMS,一旦HMS服务故障,整个hive的读写都将会受到影响。
3、由于核心节点只有3个,EMR集群将hdfs的block副本数设置为1,也就意味着hdfs的block没有任何副本,一旦某个核心节点上的hdfs datanode宕机,则此节点上的所有block块都将丢失造成数据丢失。并且如果丢失的块超过了hdfs的限制,则hdfs将会进入到安全模式,不能对外提供写服务,这也意味这hdfs服务基本不可用。
4、master节点上有hdfs namenode,且namenode没有高可用机制,一旦namenode故障整个hdfs都将不可用,并且会影响整个集群的任务提交运行,此时整个集群也基本不可用。
5、master节点有运行hue,我们会使用hue做查询分析,一旦master节点出现故障,则hue服务将不可用,不能正常进行查询分析。
6、整个集群提供的资源不足,yarn队列经常处于满负荷的状态,任务出现排队等待、超时、获取不到资源被kill等情况。
一旦master节点出现故障宕机,那么整个EMR集群都将不可用。必须要对EMR集群进行高可用技术方案升级。
3、升级方案
针对EMR集群的升级只有一个核心思想,那就是消除当前集群中存在的所有单点风险,包括但不限于hdfs namenode的高可用,hms的高可用,hdfs的block多副本等等。
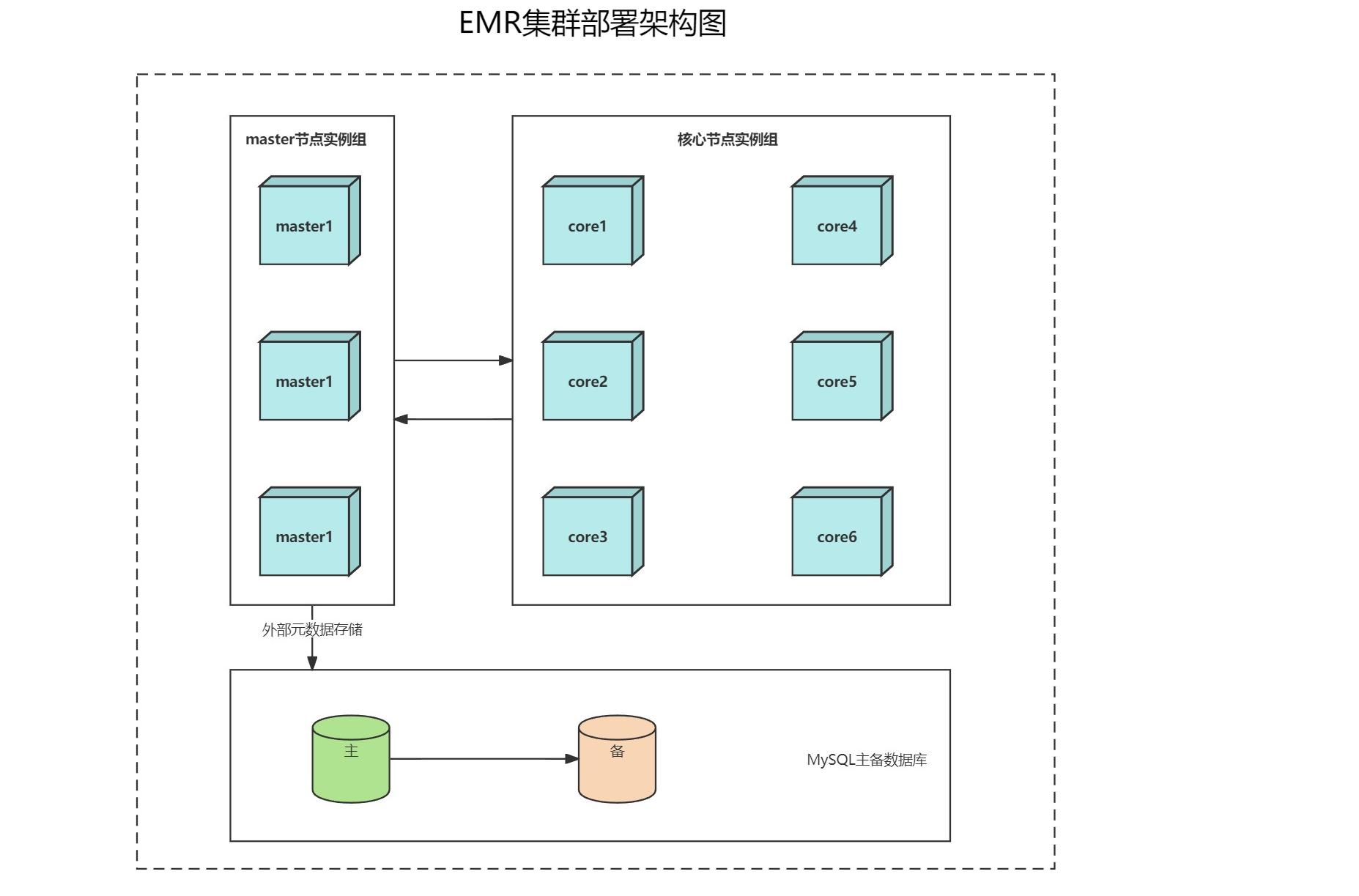
经过调研,我们决定采用如下的集群部署架构。
master节点部署多个组成实例组做HA,采用外部MySQL主备数据库作为hive,hue等组件的元数据外部持久化存储。
4、升级步骤
步骤
升级过程中只有一个核心指导方针,那就是不对原有集群造成任何影响,不对用户造成任何影响,对用户完全无感知。
所以我们采用新建集群,然后进行滚动迁移的方案进行操作。由于数据目前均存储在S3,所以不涉及数据的迁移,更多是元数据和自建服务相关的迁移。
具体步骤如下:
1、创建新的高可用架构的EMR集群。
2、集群环境初始化,包括但不限于git、python、Mongo、paimon、flink等等。
3、采用平台共用的MySQL主备数据库作为EMR集群相关组件的元数据持久化存储介质。提前创建相关database。
4、元数据迁移,采用MySQL dump的方式导出相关元数据,然后在新集群进行重放恢复。
hive元数据迁移,主要包含hive库、表、列、分区等信息。
hue元数据迁移,主要包含hue用户、权限等信息。
sheepdog元数据迁移,主要包含flink session、flink job等信息。
azkaban元数据迁移,主要包含project、flow、调度等信息。
5、自建服务迁移
sheepdog服务迁移
azkaban调度服务迁移
grafana服务迁移,域名解析
6、任务迁移
离线调度任务迁移
实时Flink任务迁移。通过savepoint方式停止,在新集群从savepoint中恢复。
7、核对确认
数据核对
任务核对
相关服务健康检查
5、风险点及回滚方案
在整个集群的迁移过程中,可能涉及的风险点如下:
1、hive元数据迁移过程中,旧集群发生元数据变化,新集群没有同步存在元数据不一致的问题?
少量数据不一致可以通过msck命令进行元数据修复,如果存在大量不一致,可能需要将旧集群的元数据重新迁移一次或者在业务低峰期将HMS服务停止进行元数据迁移,保障元数据一致性。
2、FlinkCDC任务从savepoint中恢复失败或不能恢复?
放弃从savepoint中恢复,直接从指定时间开始读取业务数据变更进行补数操作,补数完成后直接在新集群从业务数据订阅最新数据变更即可。
由于下游sink端具有冥等性,所以不会出现数据不一致情况。
3、其他未知风险?
直接切回到原有集群,保障业务不会受到较大面积、较长时间中断的影响。
6、注意事项
在集群升级过程中,同时会有两套EMR集群并行运行,待全部迁移完成后才会下线原有旧集群,所以可能会有短暂周期的集群成本增加。
core实例和task实例的区别在于core实例比task实例多了datanode的角色,因为我们的数据基本上都是存储在s3上的,所以我们可以少配置core实例多配置task实例。
core实例部署有datanode,为了满足hdfs block的多副本策略,建议配置至少4个以上的core实例。因为在core实例小于4的情况下,EMR会默认将你的hdfs副本数设置为1,此时是没有多副本的,存在数据丢失风险。
在元数据迁移过程中,因为有时间差肯定会有部分元数据不一致的情况。为了保证元数据的强一致性,建议还是选择一个业务低峰期,让元数据库进入只读状态进行迁移。
使用多主节点时,必须要在创建集群时,指定hive,hue,oozie的外部元数据存储,具体配置参考如下:
[
{
"Classification": "hive-site",
"Properties": {
"javax.jdo.option.ConnectionURL": "jdbc:mysql://hostname:3306/hive?createDatabaseIfNotExist=true",
"javax.jdo.option.ConnectionDriverName": "org.mariadb.jdbc.Driver",
"javax.jdo.option.ConnectionUserName": "username",
"javax.jdo.option.ConnectionPassword": "xxx"
}
},
{
"Classification": "hue-ini",
"Properties": {},
"Configurations": [
{
"Classification": "desktop",
"Properties": {},
"Configurations": [
{
"Classification": "database",
"Properties": {
"name": "hue",
"user": "username",
"password": "xxx",
"host": "hostname",
"port": "3306",
"engine": "mysql"
},
"Configurations": []
}
]
}
]
},
{
"Classification": "oozie-site",
"Properties": {
"oozie.service.JPAService.jdbc.driver": "org.mariadb.jdbc.Driver",
"oozie.service.JPAService.jdbc.url": "jdbc:mysql://hostname:3306/oozie?createDatabaseIfNotExist=true",
"oozie.service.JPAService.jdbc.username": "username",
"oozie.service.JPAService.jdbc.password": "xxx"
},
"Configurations": []
}
]
7、总结
runbook的重要性再怎么强调都不为过,提前准备好完整详细的runbook。
充分考虑到所有的风险点,以及所有的风险应对预案,保障服务不会出现大面积长时间中断。
做好充分的测试工作,不要把未经测试的功能升级到新集群上。
充分了解你的集群,你的业务架构,甚至是你的业务代码。以便在出现未知异常时能够紧急快速修复。
通知你的相关使用方,避免出现未通知造成使用方发现异常的情况。
做好备份工作。
待集群迁移完成后,不要立即终止原集群,而是手动停止原集群上的相关服务,确认没有任何影响后再彻底终止你的原集群。
8、参考资料
作者介绍
- 冯成杨 资深大数据开发工程师