前言
前面有讲过因为主机内存资源不足导致主机及pod均NotReady的状态,今天分享一个因为主机磁盘资源不足导致pod Evicted的故障。
故障现象
收到告警,有大量pod处于Evicted状态。
故障排查
查看告警后发现有问题的pod,均是调度到了同一台主机后出现的Evicted异常:
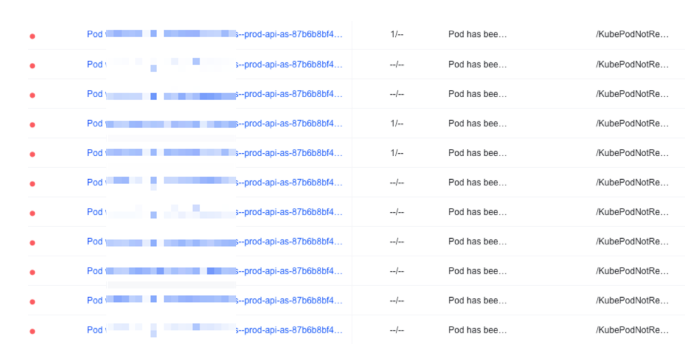 登陆容器,查看pod状态,发现存在pod处于Evicted状态,但是已经有pod迁移到了其他主机,且状态运行正常。
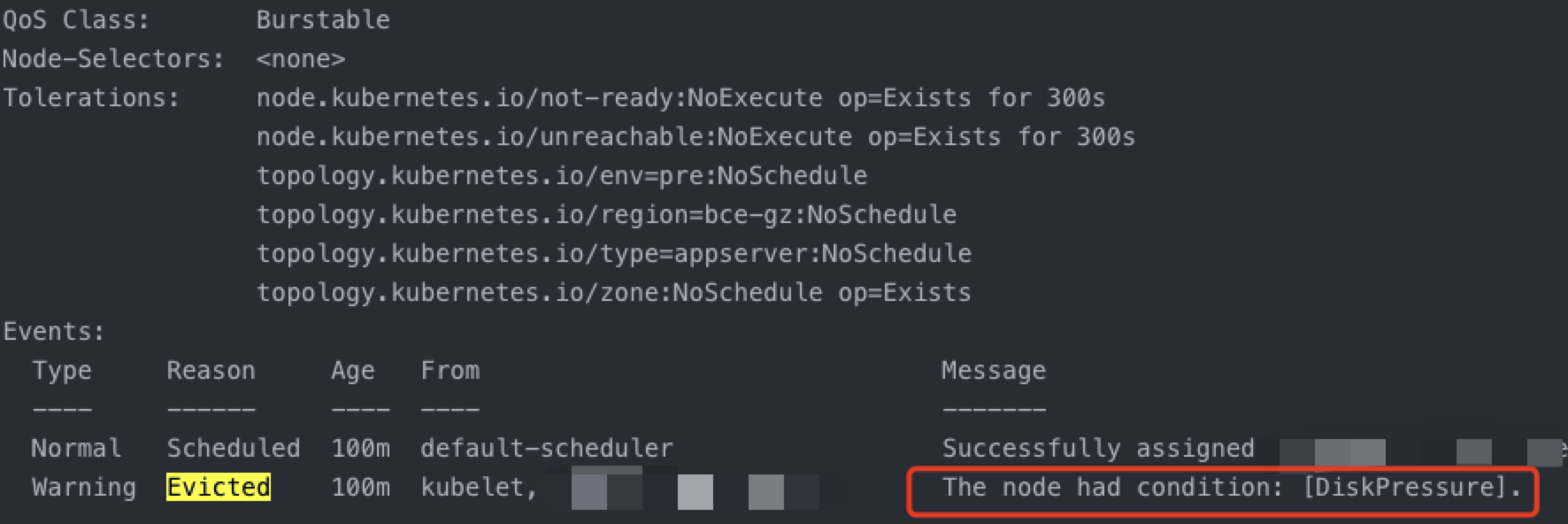
查看Evicted状态的pod,发现提示DiskPressure:
登陆容器,查看pod状态,发现存在pod处于Evicted状态,但是已经有pod迁移到了其他主机,且状态运行正常。
查看Evicted状态的pod,发现提示DiskPressure:
 查看主机状态发现主机运行正常:
查看主机状态发现主机运行正常:
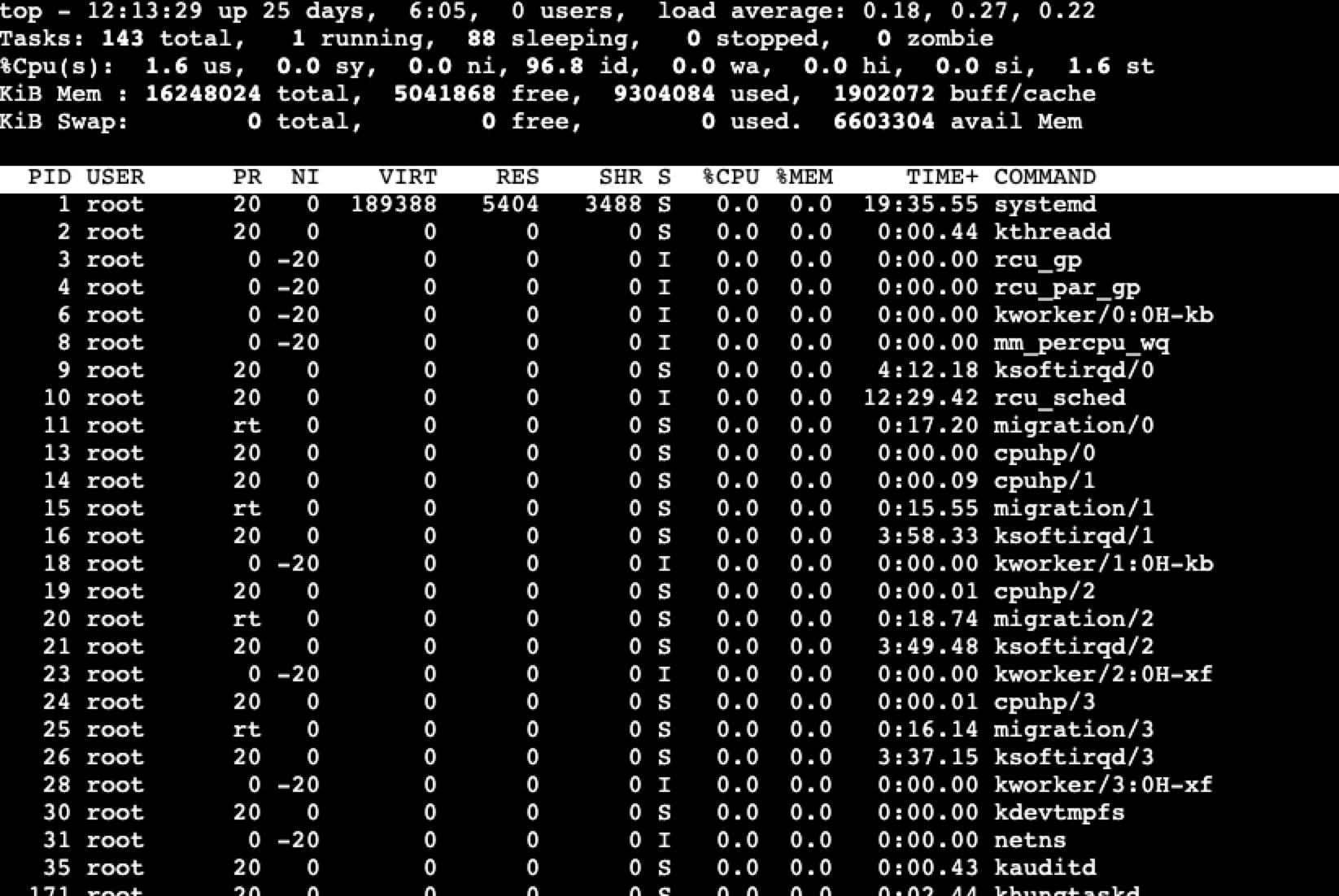
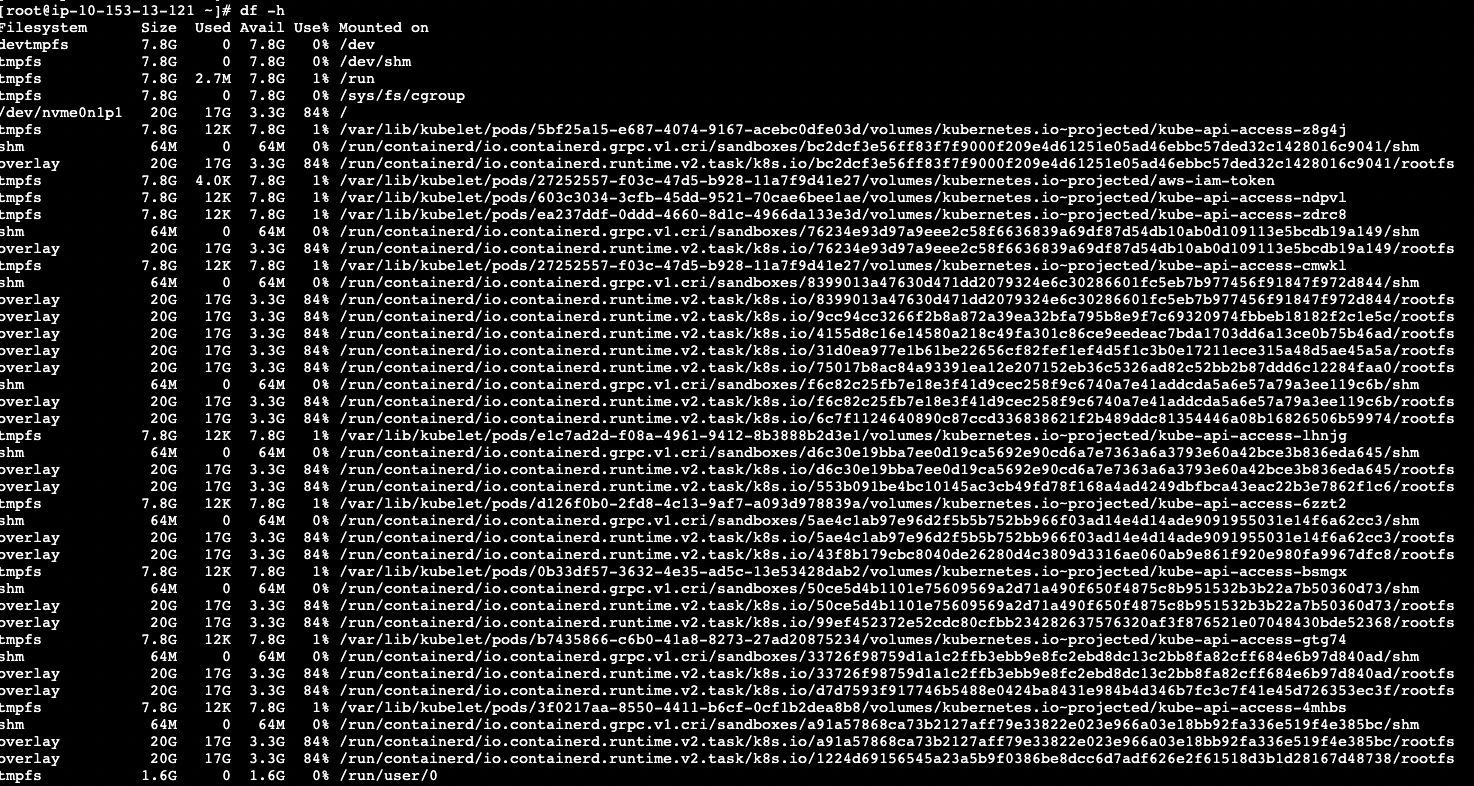
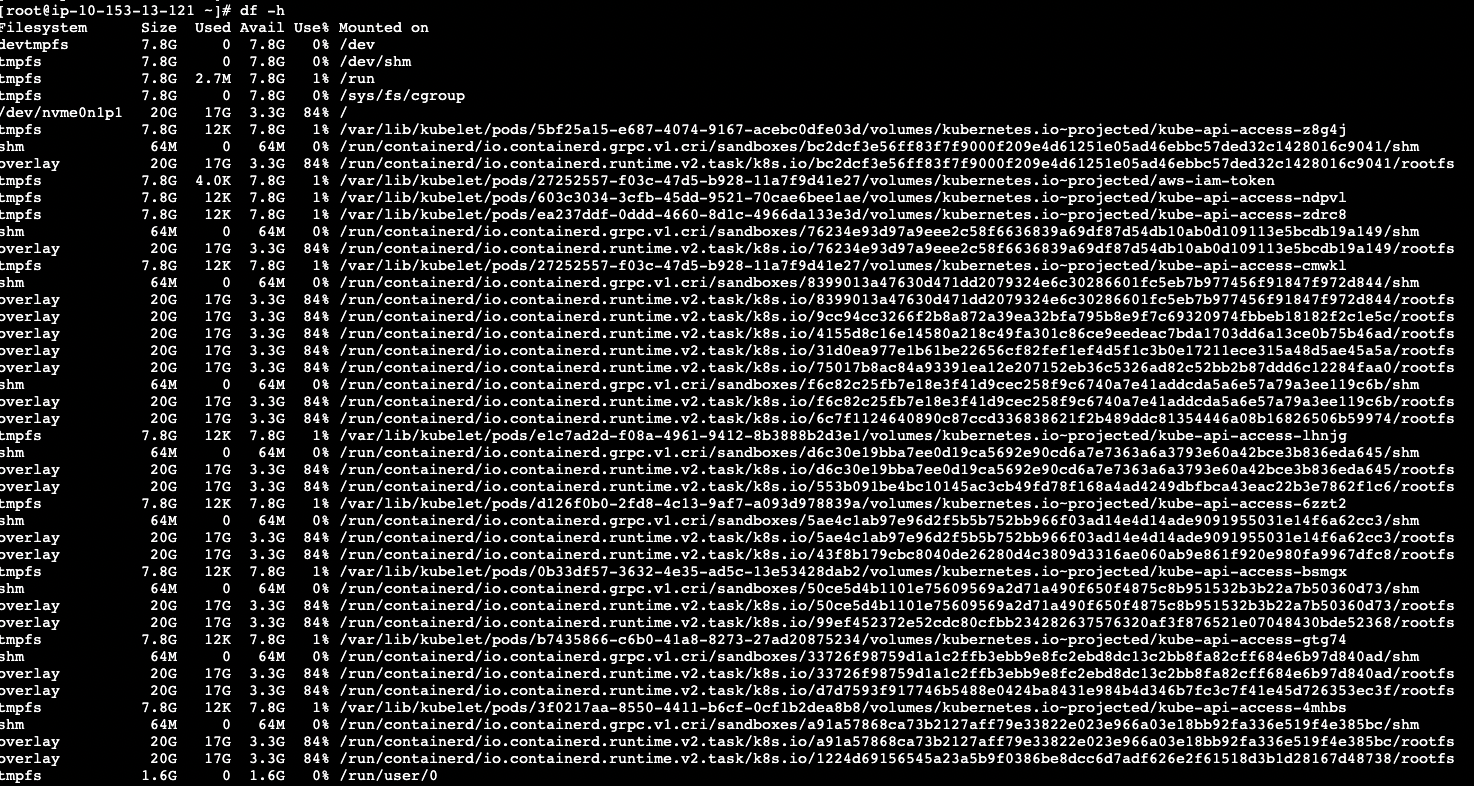
 登陆主机,查看主机监控,发现cpu使用率,内存使用率,负载正常,但是磁盘使用率处于84%:
登陆主机,查看主机监控,发现cpu使用率,内存使用率,负载正常,但是磁盘使用率处于84%:

 查看kubelet配置:
查看kubelet配置:
cat /etc/kubernetes/kubelet/kubelet-config.json
---
...
"evictionHard": {
"memory.available": "100Mi",
"nodefs.available": "10%",
"nodefs.inodesFree": "5%"
}
...
查看kubelet启动进程:
[root@ip-10-153-13-121 ~]# ps -ef| grep kube
root 3226 1 2 Nov03 ? 13:56:53 /usr/bin/kubelet --cloud-provider aws --config /etc/kubernetes/kubelet/kubelet-config.json --kubeconfig /var/lib/kubelet/kubeconfig --container-runtime remote --container-runtime-endpoint unix:///run/containerd/containerd.sock --node-ip=10.153.13.121 --pod-infra-container-image=602401143452.dkr.ecr.ap-southeast-1.amazonaws.com/eks/pause:3.5 --v=2 --node-labels=karpenter.sh/capacity-type=on-demand,karpenter.sh/provisioner-name=default
root 3683 3385 0 Nov03 ? 00:08:24 kube-proxy --v=2 --config=/var/lib/kube-proxy-config/config
nfsnobo+ 3880 3471 0 Nov03 ? 03:08:12 /bin/node_exporter --web.listen-address=127.0.0.1:9100 --path.sysfs=/host/sys --path.rootfs=/host/root --no-collector.wifi --no-collector.hwmon --collector.filesystem.mount-points-exclude=^/(dev|proc|sys|run/k3s/containerd/.+|var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/) --collector.netclass.ignored-devices=^(veth.*|[a-f0-9]{15})$ --collector.netdev.device-exclude=^(veth.*|[a-f0-9]{15})$
65532 4099 3471 0 Nov03 ? 00:11:15 /usr/local/bin/kube-rbac-proxy --logtostderr --secure-listen-address=[10.153.13.121]:9100 --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305 --upstream=http://127.0.0.1:9100/
root 8943 5189 0 12:23 pts/0 00:00:00 grep --color=auto kube
经过排查,kubelet默认并没有显示设置磁盘驱除策略,但是aws默认是有kubelet磁盘超过85%驱除的策略的:
 通过ssh登陆主机,查看相关配置,排查故障产生的原因:
通过ssh登陆主机,查看相关配置,排查故障产生的原因:
由于主机磁盘超过85%所以触发了kubelet自动驱除策略,又因为所在集群节点较少,所以新的pod又一次调度到同一个机器内。
因此一直处于pod删除调度的死循环状态,直到触发了karpenter的自动扩容策略,pod调度新的节点后才缓解此问题。
故障处理
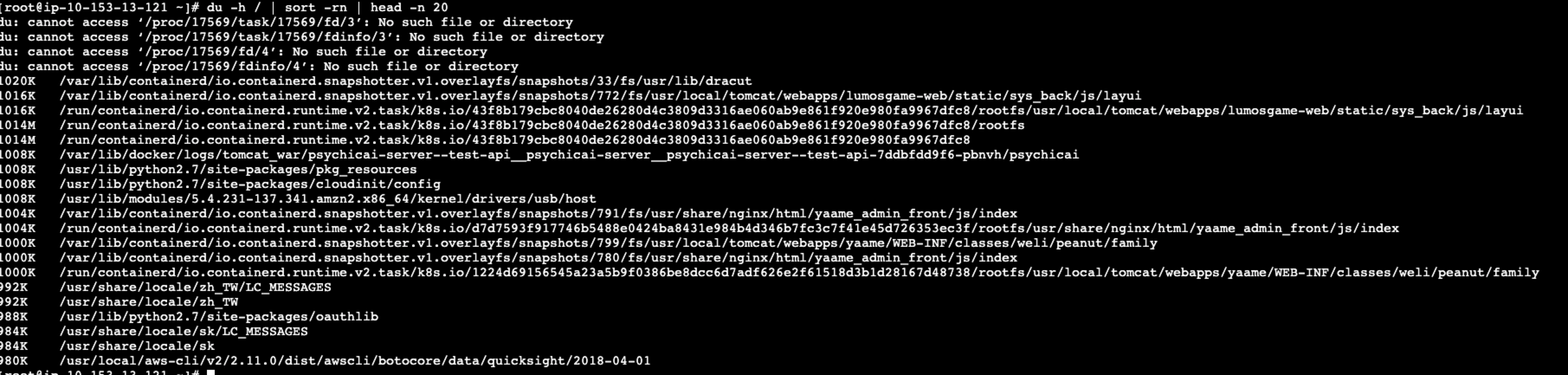
在清理主机磁盘时发现此node主机仅跑了两个业务pod,并且业务pod所占用的磁盘并不大,而且主机内也没有delete等进程占用导致磁盘没有清理:

 通过du命令查看主机磁盘状态,发现占用较大的为容器快照:
通过du命令查看主机磁盘状态,发现占用较大的为容器快照:
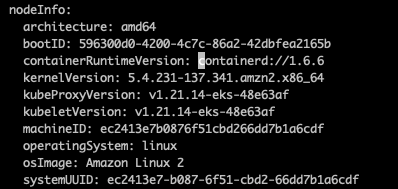
 通过查看主机状态发现主机容器引擎为contered:
通过查看主机状态发现主机容器引擎为contered:
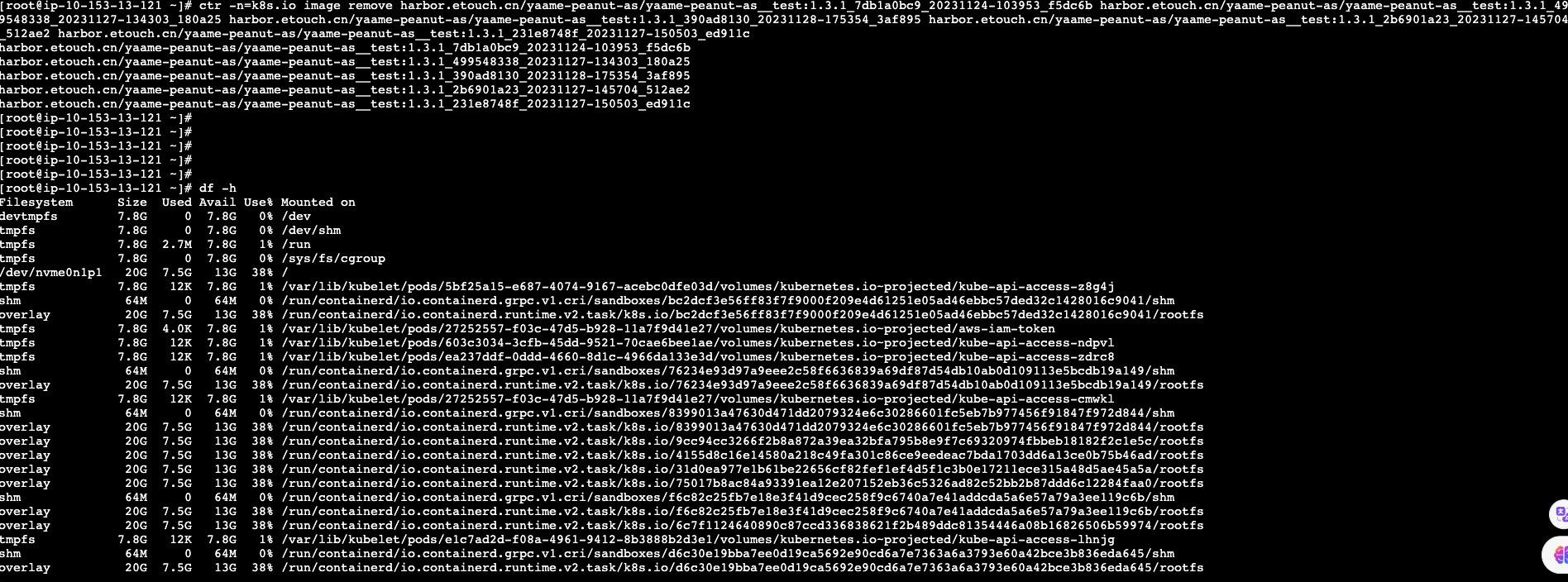
 查看主机目前镜像列表,并清除:
查看主机目前镜像列表,并清除:
故障原因
- node主机磁盘较小,kubelet未修改驱除条件,导致pod在磁盘85%的时候被驱除。
- 因为节点较少导致pod驱除后重复调度该节点。
- 因为容器引擎采用的是contered,所以主机磁盘和pod磁盘大小无法匹配,且无法通过docker prune去批量清理。
优化及解决方案
- 自定义托管节点,修改kubelet驱除条件,将磁盘占比85%驱除的条件修改为磁盘占比95%再进行驱除。
- 修改karpenter节点模版增加磁盘大小为200G。
- 如果不设置,默认karpenter自动创建出来的k8s节点磁盘大小为20G,可以通过修改karpenter的节点模版来改变磁盘大小,从而避免因为磁盘太小而频繁驱除pod的情况。
- 调整磁盘监控告警阈值,让磁盘告警阈值低于节点驱除pod的阈值。
- 能够提前发现磁盘问题,避免pod因为主机磁盘资源不足而不能调度的问题。
作者介绍
- 廉帅 高级SRE工程师