1、问题现象
hdfs 其中一个datanode宕机后,在此datanode上的block损坏,导致hdfs进入安全模式。
在hdfs的首页可以当前safe mode是on开启的状态。表明当前HDFS已经进入安全模式。
2、什么是安全模式
Hdfs 的安全模式,即 HDFS safe mode, 是 HDFS 文件系统的一种特殊状态,在该状态下,hdfs 文件系统只接受读数据请求,而不接受删除、修改等变更请求,当然也不能对底层的 block 进行副本复制等操作。
从本质上讲,安全模式 是 HDFS 的一种特殊状态,而 HDFS 进入该特殊状态的目的,是为了确保整个文件系统的数据一致性/不丢失数据,从而限制用户只能读取数据而不能改动数据的。
3、进入安全模式的情况
被动进入
被动进入一般是管理员人工处理进入,例如需要进行集群运维、扩容等场景。
可以通过如下命令进入安全模式
hdfs dfsadmin -safemode enter
处理完成后通过如下命令可以退出安全模式
hdfs dfsadmin -safemode leave
主动进入
相对来说,主动进入安全模式的场景更多。此时HDFS 在特殊状况下,为了保证整个文件系统的数据一致性/整个文件系统不丢失数据,而主动进入的一种自我保护状态。
在NameNode主节点启动时,HDFS首先会进入安全模式,datanode在启动的时候会向namenode汇报可用的block等状态,当整个系统达到安全标准时,HDFS自动离开安全模式。如果HDFS处于安全模式下,则文件block不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于datanode启动时的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求)。
系统什么时候才离开安全模式,需要满足哪些条件?
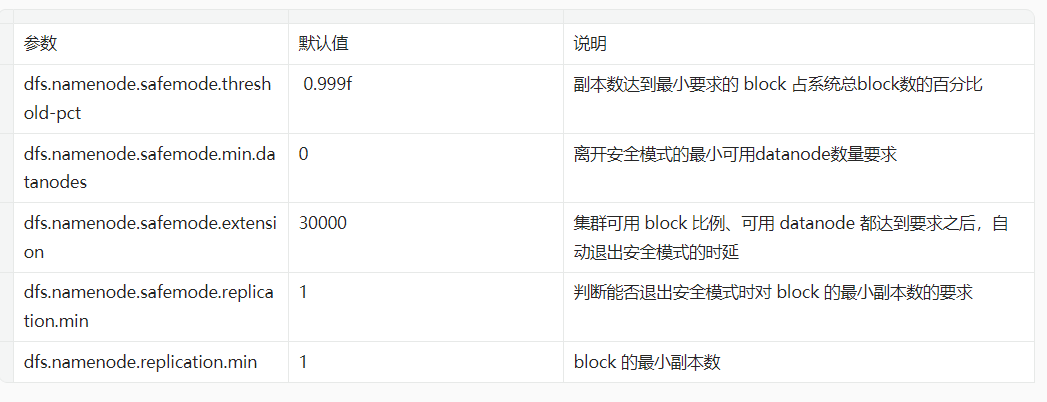
● HDFS 底层启动成功并能够跟 namenode 保持定期心跳的 datanode 的个数没有达到指定的阈值, 阈值通过 dfs.namenode.safemode.min.datanodes参数 指定;
● HDFS副本数达到最小要求的block占系统总block数的百分比,当实际比例超过该配置后,才能离开安全模式(但是还需要其他条件也满足)。默认为0.999f,也就是说符合最小副本数要求的block占比超过99.9%时,并且其他条件也满足才能离开安全模式。如果为小于等于0,则不会等待任何副本达到要求即可离开。如果大于1,则永远处于安全模式。配置通过dfs.namenode.safemode.threshold-pct指定;
● 当然如果 HDFS 底层启动成功并能够跟 namenode 保持定期心跳的 datanode 的个数没有达到指定的阈值,此时HDFS 底层达到最小副本数要求的 block 的百分比一般也都不会达到指定的阈值;
● 最小的文件block副本数量达到要求,通过dfs.namenode.replication.min参数指定,默认为1;
● dfs.namenode.safemode.extension: 当集群可用block比例,可用datanode都达到要求之后,如果在extension配置的时间段之后依然能满足要求,此时集群才离开安全模式。单位为毫秒,默认为1.也就是当满足条件并且能够维持1毫秒之后,离开安全模式。 这个配置主要是对集群的稳定程度做进一步的确认。避免达到要求后马上又不符合安全标准。
从现实情况来看,常见的HDFS进入安全模式的直接原因有:
● 部分 datanode 启动失败或者因为网络原因与 namenode 心跳失败;
● 部分 datanode 节点存储 hdfs 数据的磁盘卷有损坏,导致存储在该磁盘卷中的数据无法读取;
● 部分 datanode 节点存储 hdfs 数据的磁盘分区空间满,导致存储在该磁盘卷中的数据无法正常读取;
hdfs安全模式参数一览
4、如何解决
分析原因
当 HDFS 主动进入安全模式后,首先需要分析其主动进入安全模式的原因,可以通过以下途径进行分析:
1. 在hdfs webui页面查看当前集群的状态,datanode的状态等,了解当前集群整体情况。
2. 查看相关日志,一般是在/var/log/xxx下,查看详细日志寻找有价值的信息。
修复问题
通过以上排查确认进入安全模式的原因后,就可以进行针对性的修复了:
● 比如如果有 datanode 未启动成功,则尝试修复并启动对应的 datanode;
● 比如如果有 datanode 存储 hdfs 数据的磁盘分区空间满,则尝试扩展磁盘分区空间;
● 比如如果有 datanode 存在存储卷故障,则尝试修复存储卷,如果无法修复则需要替换存储卷(会丢失存储卷上的数据);
● 需要注意的是,如果出现了某些 datanode 节点彻底损坏无法启动,或某些 datanode 节点磁盘卷故障彻底无法修复的情况,则这些数据对应的 block 及 block 上层的 hdfs 文件,就被丢失了,后续可能需要联系业务人员补数据(从上游重新拉取数据,或重新运行作业生成数据),如果业务人员也无法补数据,这些数据就被彻底损坏无法恢复了;
● 可以通过如下命令查看丢失的 block 及这些 block 对应的上层 hdfs 文件,并记录下来后续交给业务人员去判断是否需要补数据:hdfs fsck / -list-corruptfileblocks,hdfs fsck / -files -blocks -locations;
● 对于不存在数据丢失的情况,按照上述方式修复并重启集群后,HDFS 就会退出安全模式并正常对外提供读写服务;
● 对于存在数据丢失的情况,需要通过如下命令手动退出安全模式并删除损坏的/丢失的 block 对应的上层 hdfs 文件:
1、退出安全模式(只有退出安全模式才能删除数据):sudo -u hdfs hdfs dfsadmin -safemode leave;
2、删除丢失的 blockd 对应的上层 hdfs 文件(自动检查文件系统并把丢失的block的上层hdfs文件删除):sudo -u hdfs hdfs fsck / -delete;
3、在删除了丢失的 block 对应的上层 hdfs 文件后,HDFS 底层达到最小副本数要求的 block 的百分比就达到了指定的阈值(总文件数降低了总 block数也相应降低了,所以成功汇报的block的百分比就相应上升达到阈值了),所以重启后也就能够正常退出安全模式并正常对外提供读写服务了。
5、生产完整处理流程
注意以下所有命令都需要在hdfs用户下执行,可以使用su -hdfs切换执行。
1、首先退出安全模式
sudo -u hdfs hdfs dfsadmin -safemode leave
2、检查当前hdfs状态
hdfs dfsadmin -report
3、列出hdfs文件系统上所有corrupted blocks path
hdfs fsck -list-corruptfileblocks
4、检查健康状态
hdfs fsck /
5、查看损坏的块的具体信息
hdfs fsck /path/to/corrupt/file -locations -blocks -files
6、删除这些坏块
hdfs fsck / -delete
该指令将会删除 path“/”下的missing and corrupted blocks;此外,您可能需要根据第4步的结果来修改为指定的path。
7、再次检查是否是healthy状态("The filesystem under path '/' is HEALTHY");删除blocks需要时间,因此如果仍是unhealthy可以稍后再来检查。
hdfs fsck -list-corruptfileblocks
8、有些情况下 文件在第5步并未成功能被删除,因此您可以运行以下指令来将他们从hdfs删除:
hdfs dfs -rm "/File/Path/of/the/missing/blocks"
按照上述步骤处理完成,正常情况下hdfs会恢复正常。
6、总结
● hdfs的高可用需要注意,生产环境block副本数建议最少2副本。
● 关注hdfs各datanode的磁盘使用情况,超出阈值及时进行扩容。
● 如果hdfs进入安全模式,要先进行分析。切勿直接强制退出安全模式。
● 如果hdfs进入安全模式是因为block损坏导致的,先尝试从其他副本进行block恢复,切勿直接强行删除损坏的block。如果实在恢复不出来,在进行损坏block的删除,并在删除后尝试从上游恢复这个数据,比如业务重新写入。
● 生产安全模式相关参数的修改要慎重,切勿直接修改相关参数使hdfs退出安全模式。
作者介绍
- 冯成杨 资深大数据开发工程师