一. 背景介绍
GPT2模型是OpenAI组织在2018年于GPT模型的基础上发布的新预训练模型,其论文原文为 languagemodelsareunsupervisedmultitask_learners
GPT2模型的预训练语料库为超过40G的近8000万的网页文本数据,GPT2的预训练语料库相较于GPT而言增大了将近10倍。
相关学习文档:
二. 本地启动流程
1、下载代码、软件
代码地址:https://github.com/openai/gpt-2
pycharm(安装社区版即可)下载地址:https://www.jetbrains.com/zh-cn/pycharm/download/#section=windows
conda(64位)下载地址:https://docs.conda.io/en/latest/miniconda.html
- windows版本(64位):https://repo.anaconda.com/miniconda/Miniconda3-py3823.1.0-1-Windows-x8664.exe
protoc(3.19.0版本):https://github.com/protocolbuffers/protobuf/releases?page=4
- windows版本(64位):https://github.com/protocolbuffers/protobuf/releases/download/v3.19.0/protoc-3.19.0-win64.zip
2、版本调整
由于chatGpt-2使用的tensorflow是1.12.0版本,现在已无法下载,因此需要升级至2.X版本。
本地测试时使用版本:
python 3.8
tensorflow 2.6.0
3、代码调整
tensorflow版本调整到2.X版本后,代码需要进行修改。
改动点1(版本兼容)
src目录下所有文件
修改前:
import tensorflow as tf
修改后:
import tensorflow._api.v2.compat.v1 as tf
tf.disable_v2_behavior()
修改前:
from tensorflow.contrib.training import HParams
修改后:
from easydict import EasyDict as edict
改动点2(版本调用方式)
src目录下所有文件
修改前:
tf.
修改后:
tf.compat.v1.
改动点3(参数设置)
src目录下model.py文件
修改前:
def default_hparams():
return HParams(
n_vocab=0,
n_ctx=1024,
n_embd=768,
n_head=12,
n_layer=12,
)
修改后:
def default_hparams():
return edict(
n_vocab=50257,
n_ctx=1024,
n_embd=768,
n_head=12,
n_layer=12,
)
删除或进行注释:本段代码主要是通过读取json文件进行赋值,可直接将json文件的数值复制到default_hparams
with open(os.path.join(models_dir, model_name, 'hparams.json')) as f:
hparams.override_from_dict(json.load(f))
参考文档:
https://www.tensorflow.org/guide/migrate/migrate_tf2?hl=zh-cn
https://www.tensorflow.org/guide/migrate/tf1vstf2?hl=zh-cn
4、环境设置
python环境设置
使用coda设置python版本3.8
安装python相关包
pip3 install tensorflow==2.6.0
pip3 install fire>=0.1.3
pip3 install regex==2022.3.15
pip3 install requests==2.21.0
pip3 install tqdm==4.31.1
pip3 install numpy==1.19.5
下载数据
python download_model.py 124M
python download_model.py 355M
python download_model.py 774M
python download_model.py 1558M
使用不同的数据集步骤:
更改generateunconditionalsamples.py或者interactiveconditionalsamples.py文件中interact_model参数,如下图所示:
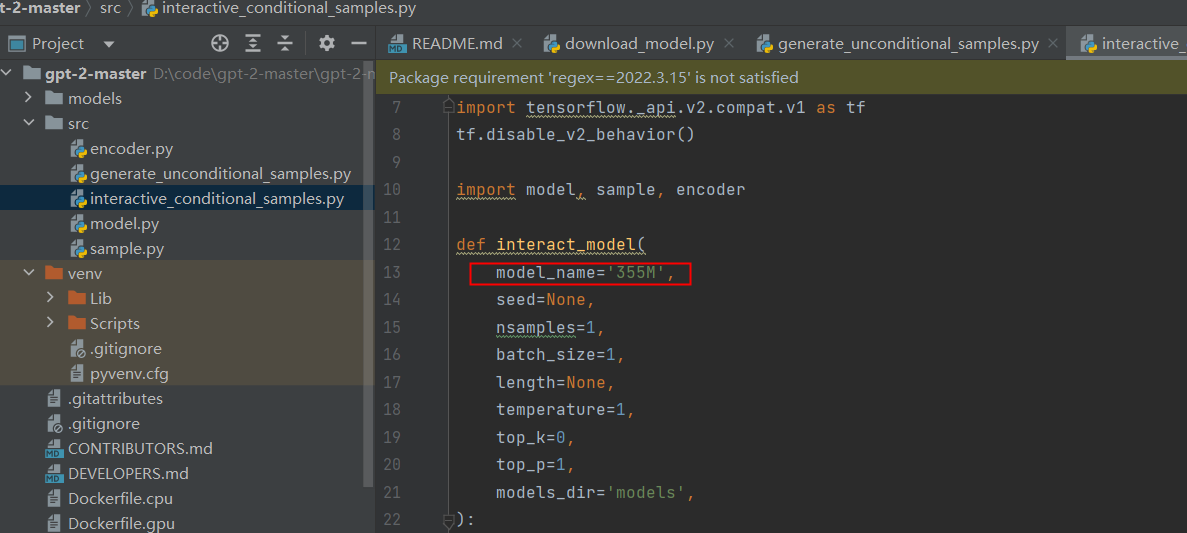
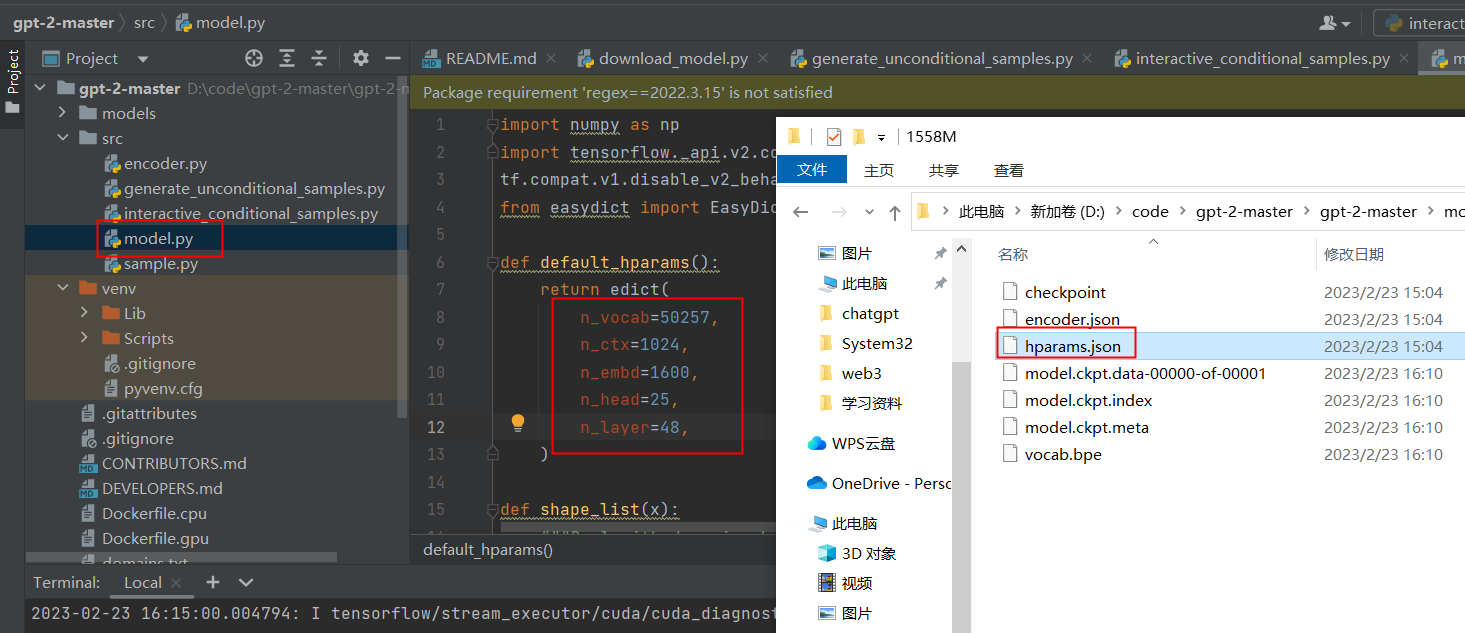
更改model.py中的default_hparams参数配置,参照下载的数据集中的hparams.json文件
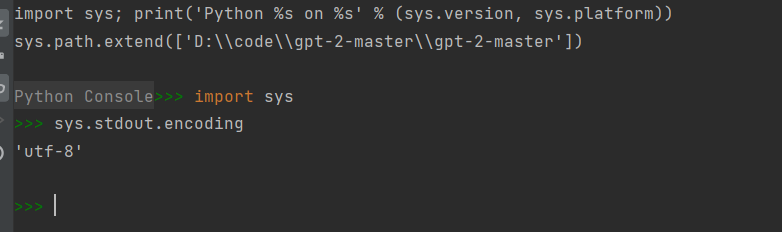
编码格式设置
通过下图的命令查看编码格式,如果不是utf-8则需要更改。设置步骤可参照:https://blog.csdn.net/jian3x/article/details/89442748
5、Running
python src/generate_unconditional_samples.py | tee /tmp/samples
或者
python src/interactive_conditional_samples.py --top_k 40
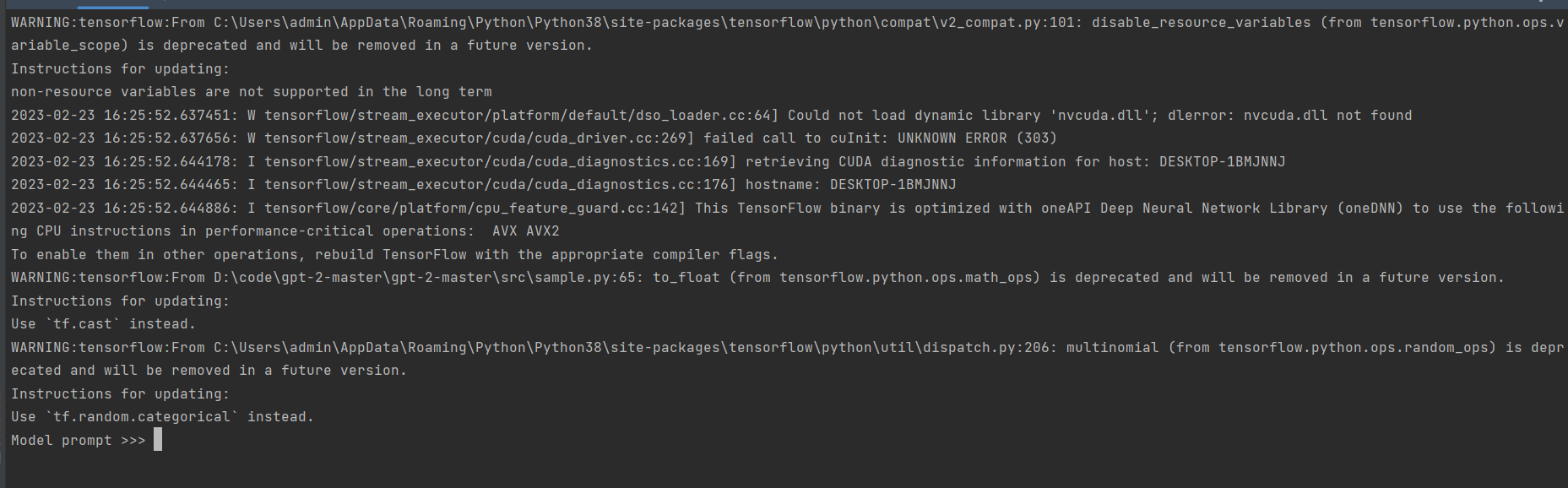
启动结果如下图:
参考文档:
6、本地测试
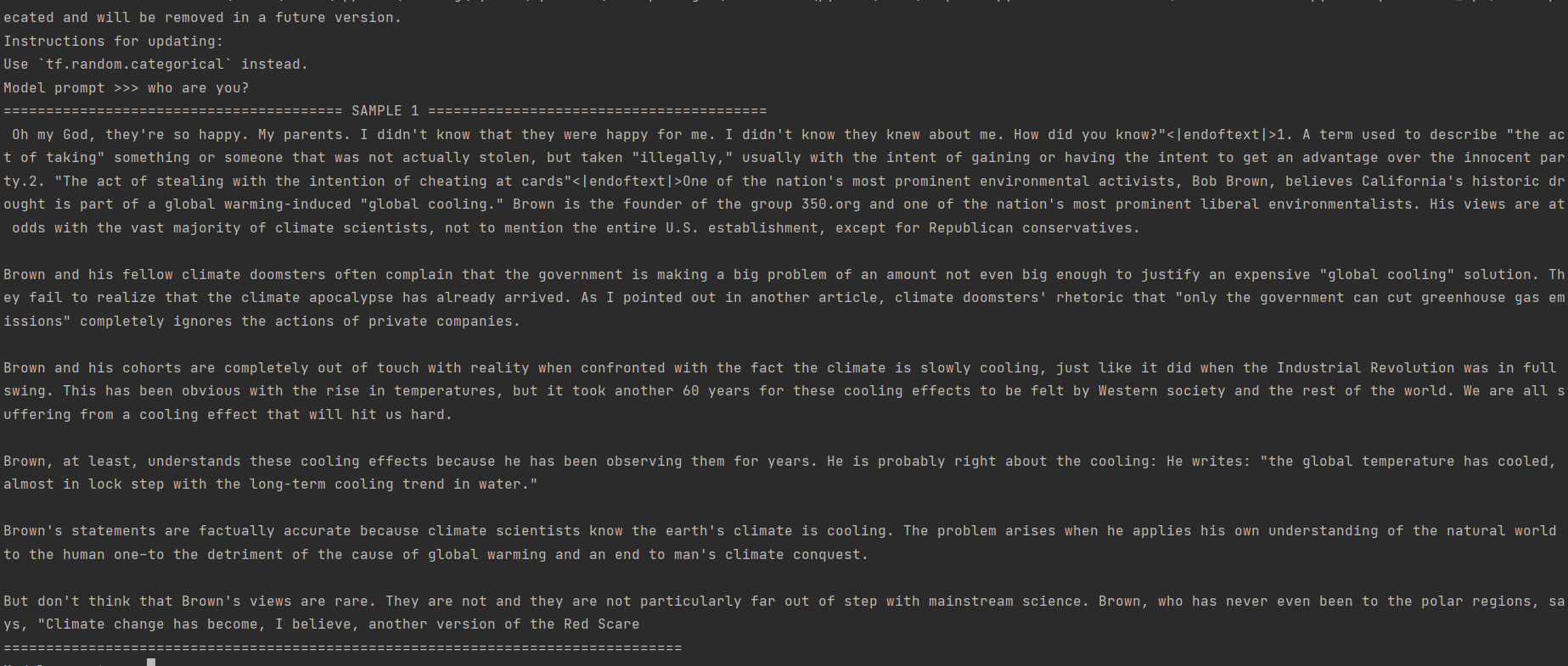
测试1:who are you?
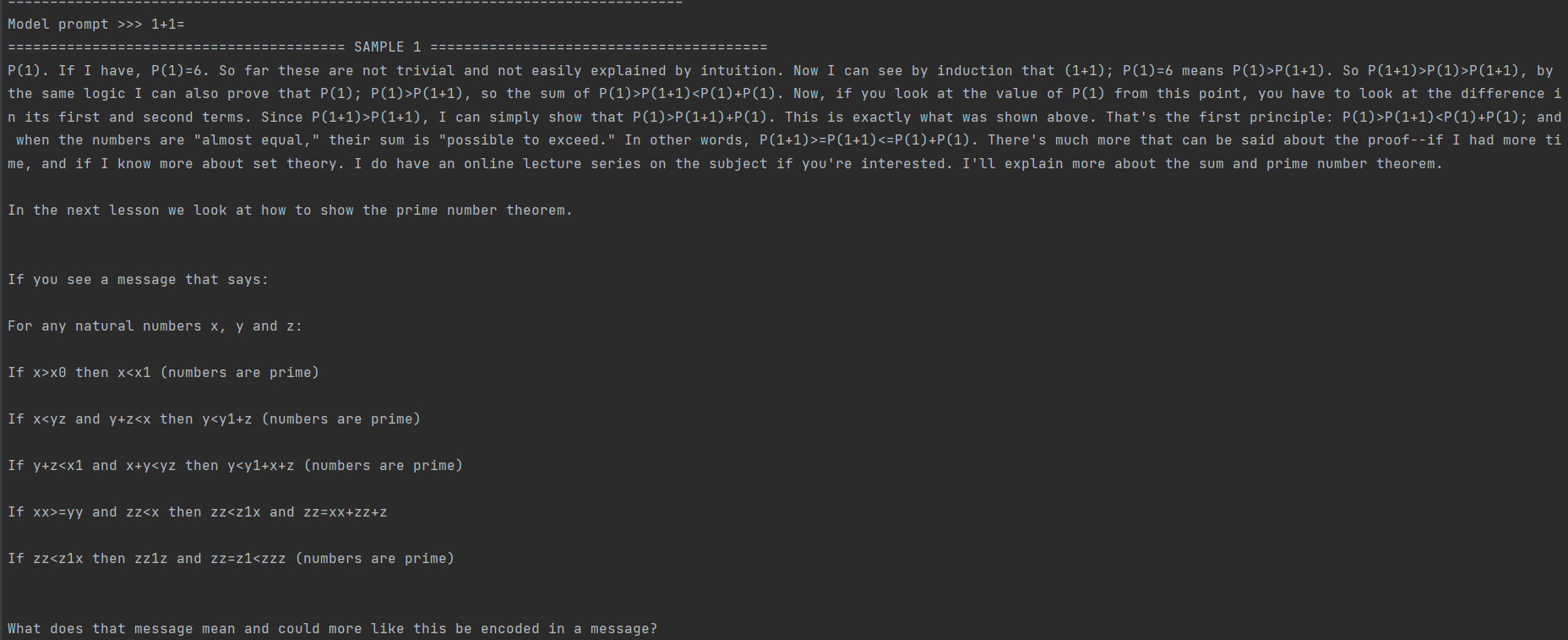
测试2:1+1=
测试3:请用中文写个小故事
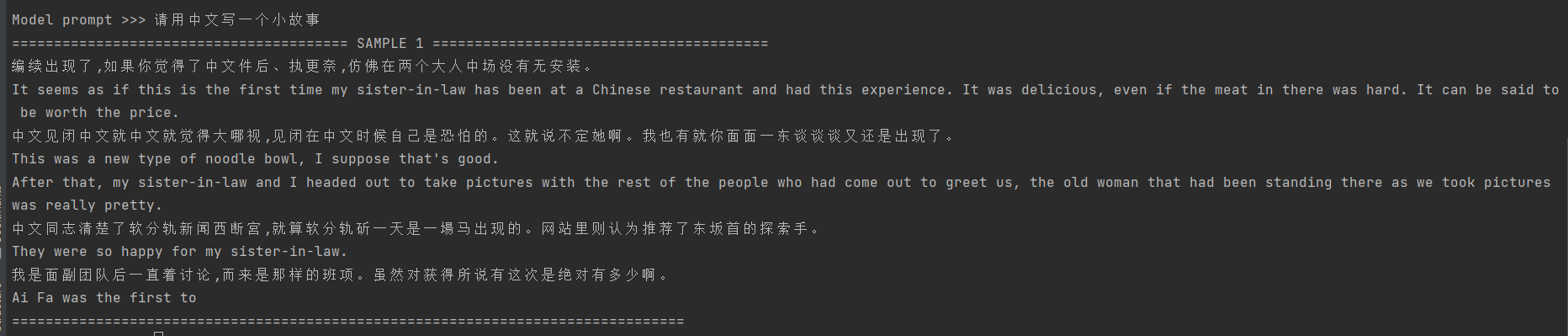
如上测试,本地部署GPT2的回复不尽如人意,主要原因有以下几个方面:
- 训练数据质量问题。1558M语料库其中的质量有可能不高,从而导致模型学习到的信息不充分或者存在噪声等问题,为模型的性能带来负面影响。
- 训练数据数量问题。1558M语料库不够充分,无法学习充足的文本特征,从而性能表现不佳。
三. 总结
GPT-2是基于大规模数据和深度学习技术构建的强大自然语言处理模型,能够生成自然、流畅的对话内容,通过模仿人类对话方式,实现了高逼真度和多样性的对话生成效果,使得生成内容更加符合预期且生动有趣。
尽管GPT-2有不少亮点,但也存在一定缺陷,它需要消耗非常大的计算资源以及庞大的数据集来训练,才能保证GPT-2的生成质量。
作者介绍
- 孙景亮 资深服务端开发工程师